3 Moodle Assignment submission reports
Lead author: Emily Nordmann
Platforms like Moodle provide extremely detailed assignment submission reports that contain data on when the student submitted, extensions, and their grade. This tutorial explains how to use R to create a series of simple reports on the data provided by Moodle Assignment Submission reports that can be helpful for generating insights into student behavior on your course. This tutorial is designed with a Moodle report in mind, but it would be possible to adapt much of this code to the reports produced by other systems.
3.1 Set-up
Install (if required) and load the following packages
library(tidyverse) # data wrangling and visualisation
library(rio) # import data
library(lubridate) # working with dates
library(plotly) # interactive plots
library(psych) # for descriptive statsThe data file is a simulated assignment submission report for 300 students for an essay submission. Although the data has been simulated, the file is identical to the one that is downloaded from Moodle so you should be able to use this code with any assignment submission reports downloaded from Moodle (assuming that the variable names don't change between institutions!).
- The assignment submission report is an .xlsx file. There are lots of functions you can use in R to import specific types of files, however, the
importfunction from theriopackage is a great wrapper function that works for pretty much any type of file and avoids me having to remember which function I need for each specific file type. - The first three lines of the assignment submission report file are blank and the main data table starts on line 4, so we add
skip = 3to skip the first three lines of data from the import.
dat <- import("https://github.com/emilynordmann/scholaRship/raw/master/book/data/essay_data.xlsx", skip = 3)3.2 Data types
Before we do anything we need to do a little work to tidy up the file and ensure that R has our data encoded as the right type. First, check the data using str():
str(dat)## 'data.frame': 300 obs. of 14 variables:
## $ # : num 1 2 3 4 5 6 7 8 9 10 ...
## $ Username : chr "Name 1" "Name 2" "Name 3" "Name 4" ...
## $ Participant No: chr "100000252" "100000128" "100000244" "100000587" ...
## $ Email address : chr "myemail@student.ac.uk" "myemail@student.ac.uk" "myemail@student.ac.uk" "myemail@student.ac.uk" ...
## $ ID number : chr "1234818" "1234694" "1234810" "1235153" ...
## $ Groups : chr "group6" "group10" "group8" "group7" ...
## $ Status : chr "submitted" "submitted" "submitted" "submitted" ...
## $ Grade : chr "C3" "C1" "A4" "C1" ...
## $ Turnitin : chr "16" "16" "12" "15" ...
## $ Grader : chr "Marker 4" "Marker 4" "Marker 4" "Marker 3" ...
## $ Modified : chr "16/11/20, 20:14" "13/11/20, 08:26" "13/11/20, 08:50" "12/11/20, 18:05" ...
## $ Released : chr "7/12/20, 12:01" "7/12/20, 12:01" "7/12/20, 12:01" "7/12/20, 12:00" ...
## $ Extension : chr "16/11/20, 12:00" "-" "-" "-" ...
## $ Files : chr "essay1" "essay2" "essay3" "essay4" ...Based on this, there's three things we need to do:
- Remove the
-Moodle uses to represent missing data and replace with an actual empty cell (i.e., anNA) usingmutate()andna_if - Convert all date and time variables to a date/time class as R currently has it stored as character.
Modified(the time the student last changed the file, i.e., when they submitted),Extension, andReleasedare currently in the format day-month-year-hour-minute so we'll use thedmy_hmfunction from thelubridatepackage. - Convert any numeric data to numeric. If a variable has any character text in it, R will read that variable in as a character. Because Moodle used
-to encode missing values, the numeric Turnitin score is represented as character variable so once we've gotten rid of the-we need to convert it back.
dat_cleaned <- dat %>%
mutate(across(where(is.character), ~na_if(., "-"))) %>% # replace - with NAs
mutate(Modified = dmy_hm(Modified),
Extension = dmy_hm(Extension),
Released = dmy_hm(Released),
Turnitin = as.numeric(Turnitin))There's a lot you can do with the data contained in this file, below are some suggestions for insights you can generate.
3.3 Extensions and late submissions
Rates of extensions and late submission increased significantly over covid and we've found it helpful to look at patterns of when students submit their work relative to the deadline.
- First, create a date time variable that contains the deadline. We'll use the same format as above as therefore use the
dmy_hmfunction again to convert this information to the right format so R recognises it as a date. The deadline you state should be the time at which the assignment would become a late submission - for us it's one minute after the stated deadline so in this example it would be 1 minute past 12 noon on 13th November 2020. - It's also helpful to have variables that store how many students were on the course in total, and how many submitted.
deadline <-dmy_hm("13/11/2020 12:01")
total_students <- nrow(dat_cleaned)
total_submissions <- dat_cleaned %>%
filter(Status == "submitted") %>%
nrow()There's a few ways we can look at the extension and late submission data. First, let's calculate the number of extensions that were applied with a simple count. The below code gives us the number of extensions for each day.
| Extension | n |
|---|---|
| 2020-11-15 12:00:00 | 2 |
| 2020-11-16 12:00:00 | 6 |
| 2020-11-17 12:00:00 | 8 |
| 2020-11-18 12:00:00 | 14 |
| 2020-11-20 12:00:00 | 9 |
| NA | 261 |
To get the total number of extensions, we adapt the same code but remove the NAs from the calculation and then sum up the total and calculate what percent of submissions had an extension applied:
dat_cleaned %>%
count(Extension) %>%
filter(!is.na(Extension)) %>% # remove rows that don't have an extension date
summarise(total = sum(n),
percent = round((total/total_submissions)*100, 2))| total | percent |
|---|---|
| 39 | 13.64 |
We might want something more fine-grained than that and need to look at the numbers of on-time submissions, extensions, late submissions, and non-submissions and this requires a bit of data wrangling.
case_when() allows you to recode values based on multiple if-then statements. Our conditions are:
- If the essay is submitted on or before the deadline, it is labelled as on-time.
- If the essay is submitted after the deadline but on or before the extension deadline, it is labelled as on-time with an extension.
3 If the essay is submitted after the deadline and there is no extension applied, it is labelled as late.
- If the essay is not submitted it is labelled as non-submission.
If this makes your head explode, please know that this code took me half an hour and multiple errors to write before I got the logic correct.
dat_cleaned <- dat_cleaned %>%
mutate(submission_category= case_when((Status == "submitted" & Modified <= deadline)~ "On-time",
(Modified > deadline & deadline <= Extension) ~ "On-time w extension",
(Modified > deadline & is.na(Extension)) ~ "Late",
(Modified > Extension) ~ "Late with extension",
TRUE ~ "Non-submission"))We can then use these new categories to calculate descriptives:
dat_cleaned %>%
count(submission_category) %>%
mutate(percent = round((n/total_submissions)*100, 2))| submission_category | n | percent |
|---|---|---|
| Late | 12 | 4.20 |
| Non-submission | 14 | 4.90 |
| On-time | 238 | 83.22 |
| On-time w extension | 36 | 12.59 |
We'll remove the non-submissions from the distribution plot as otherwise they are plotted as having been submitted when the assignment first opened:
p1 <- dat_cleaned %>%
filter(submission_category != "Non-submission") %>%
ggplot(aes(Modified, fill = submission_category)) +
geom_histogram(colour = "black") +
theme_minimal() + # add theme
theme(legend.position = "bottom") + # move legend to bottom
labs(fill = NULL, x = NULL, title = "Assignment submission report") + #labels
scale_fill_viridis_d(option = "E") + # colour blind friendly palette
theme(axis.text.x = element_text(angle=90)) + # rotate axis labels
scale_x_datetime(date_breaks = "1 day", date_labels = "%b %d") + # set breaks
geom_vline(xintercept = deadline, colour = "red", linetype = "dashed", size = 1.5) # add dashed line## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
p1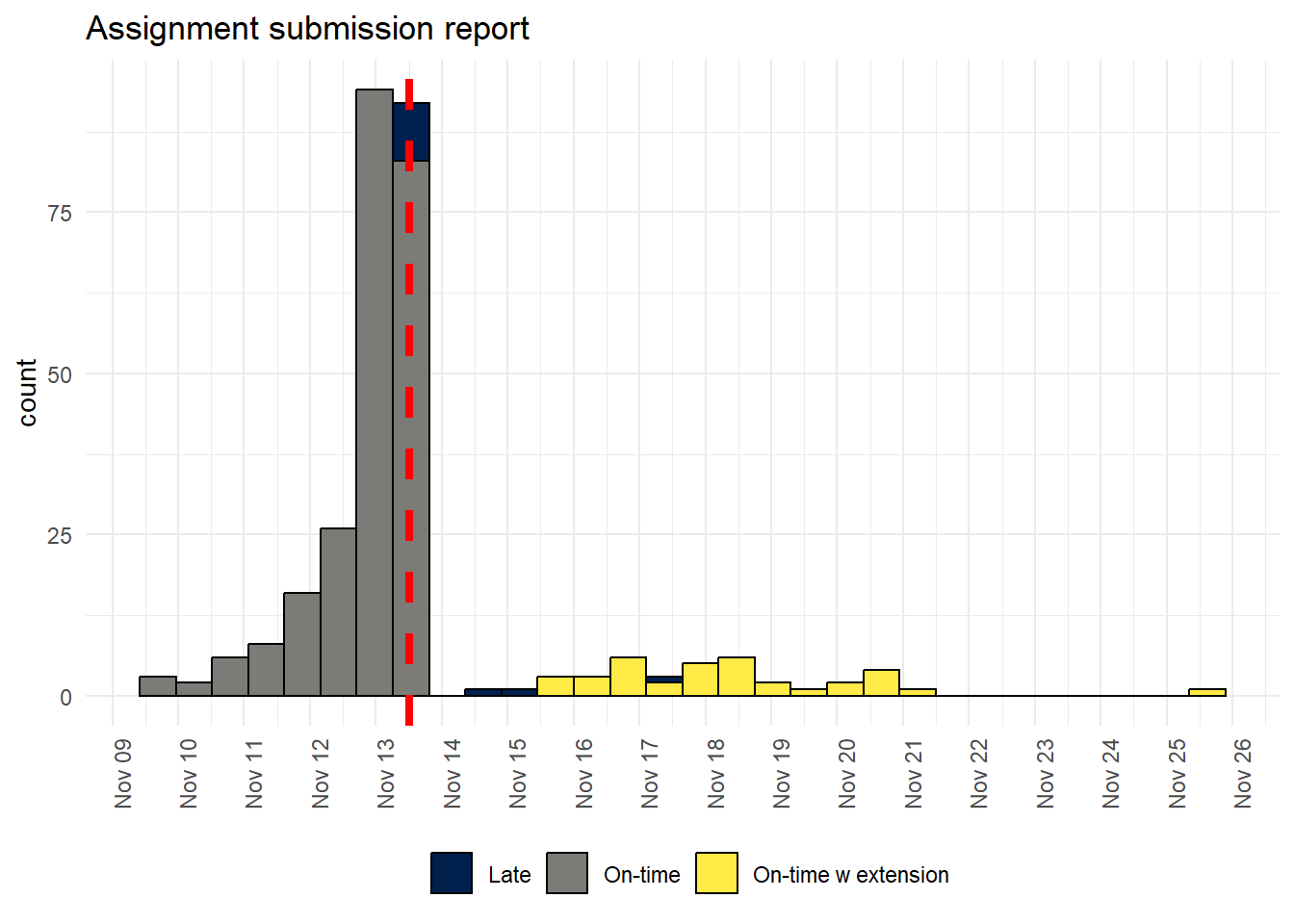
You can also produce a interactive version of the plot using ggplotly() - you can hover over the bars to see the counts and remove certain groups from the data:
ggplotly(p1)If you don't have the extensions applied through Moodle or if you just wanted to look at the difference between on-time submissions and collapse lates and extensions into one group then you could do the following:
3.4 Grades
We use a 22-point scale where each alphanumeric grade has a corresponding grade point total on a 22-point scale (e.g., a B2 = 16).The grades in Moodle are stored as in their alphanumeric form so we need to convert this to numbers.
I do this so often that the easiest way is to have a spreadsheet that contains the grades with the associated gradepoints, import this, and then use inner_join() to combine the two files. This will join the two files by their common columns, so we now have a variable Points in our dataset that has the corresponding number for the alphanumeric grade.
grade_points <- import("https://raw.githubusercontent.com/emilynordmann/scholaRship/master/book/data/grade_points.csv")
dat_cleaned <- inner_join(dat_cleaned, grade_points, by = "Grade")We can now create some basic descriptive stats and visualisations on the grade point values. The describe() function from the psych() library is great for quickly producing a range of descriptive statistics.
At this stage I want to highlight again that these are simulated data so don't read anything into the actual patterns, it's not real data, any patterns you see are meaningless
| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Points | 1 | 285 | 14.40702 | 2.800142 | 15 | 14.50655 | 2.9652 | 1 | 21 | 20 | -0.6750928 | 2.13971 | 0.1658661 |
ggplot(dat_cleaned, aes(Points)) +
geom_histogram(binwidth = 1, colour = "black") +
theme_minimal() +
labs(title = "Distribution of essay grades",
x = NULL,
colour = NULL,
subtitle = "Dashed line = mean grade") +
scale_x_continuous(breaks = seq(1,22, by = 1)) +
geom_vline(aes(xintercept=mean(Points),color="red"),
linetype="dashed",
size = 1,
show.legend = FALSE) 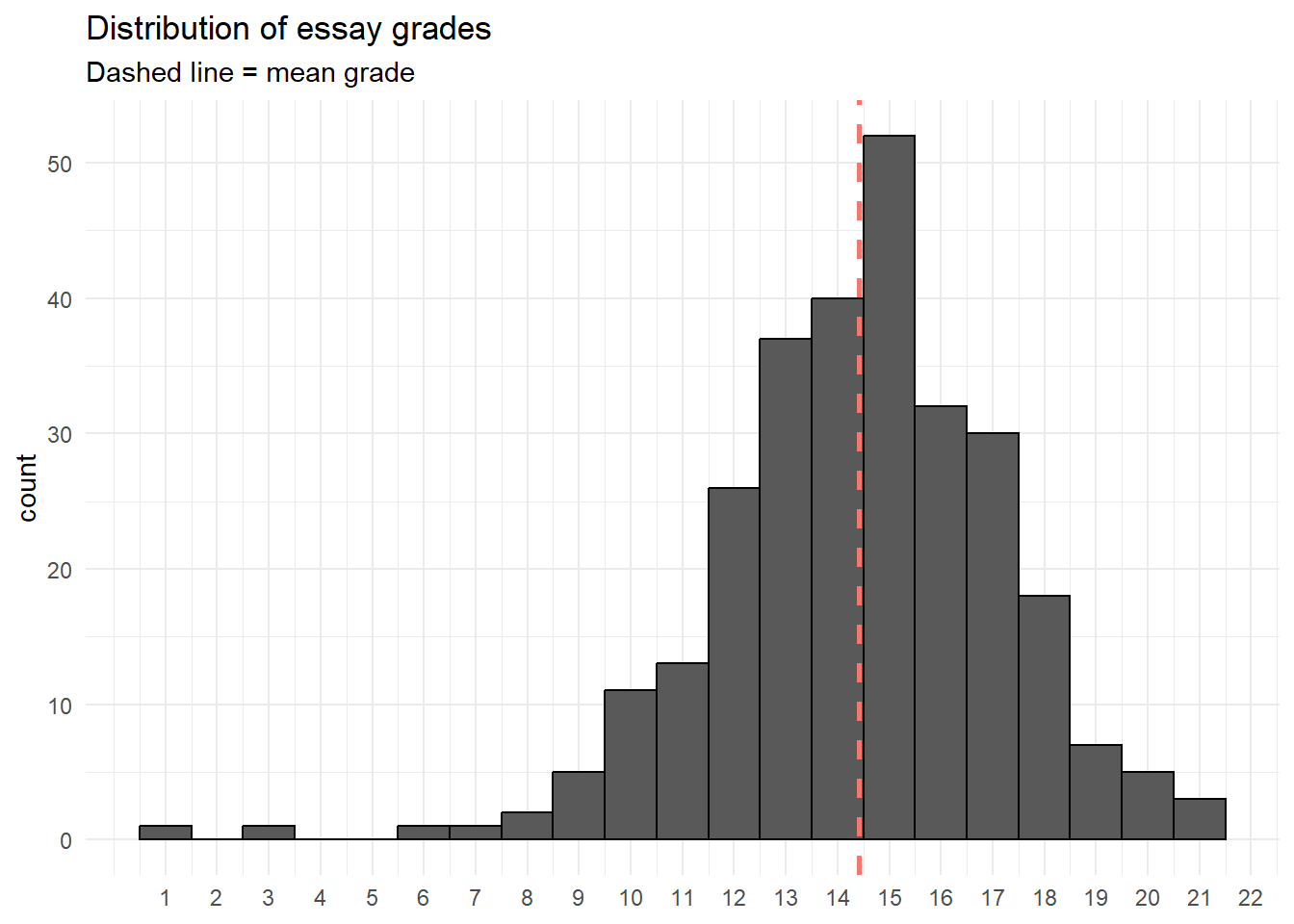
We could also look at the distribution of grades by submission category:
ggplot(dat_cleaned, aes(Points, fill = submission_category)) +
geom_histogram(binwidth = 1, colour = "black") +
theme_minimal() +
labs(title = "Distribution of essay grades",
x = NULL,
subtitle = "Dashed line = mean grade",
fill = NULL) +
geom_vline(aes(xintercept=mean(Points),color="red"),
linetype="dashed",
size=1,
show.legend = FALSE) +
scale_x_continuous(breaks = seq(1,22, by = 1)) +
theme(legend.position = "bottom") +
scale_fill_viridis_d(option = "E")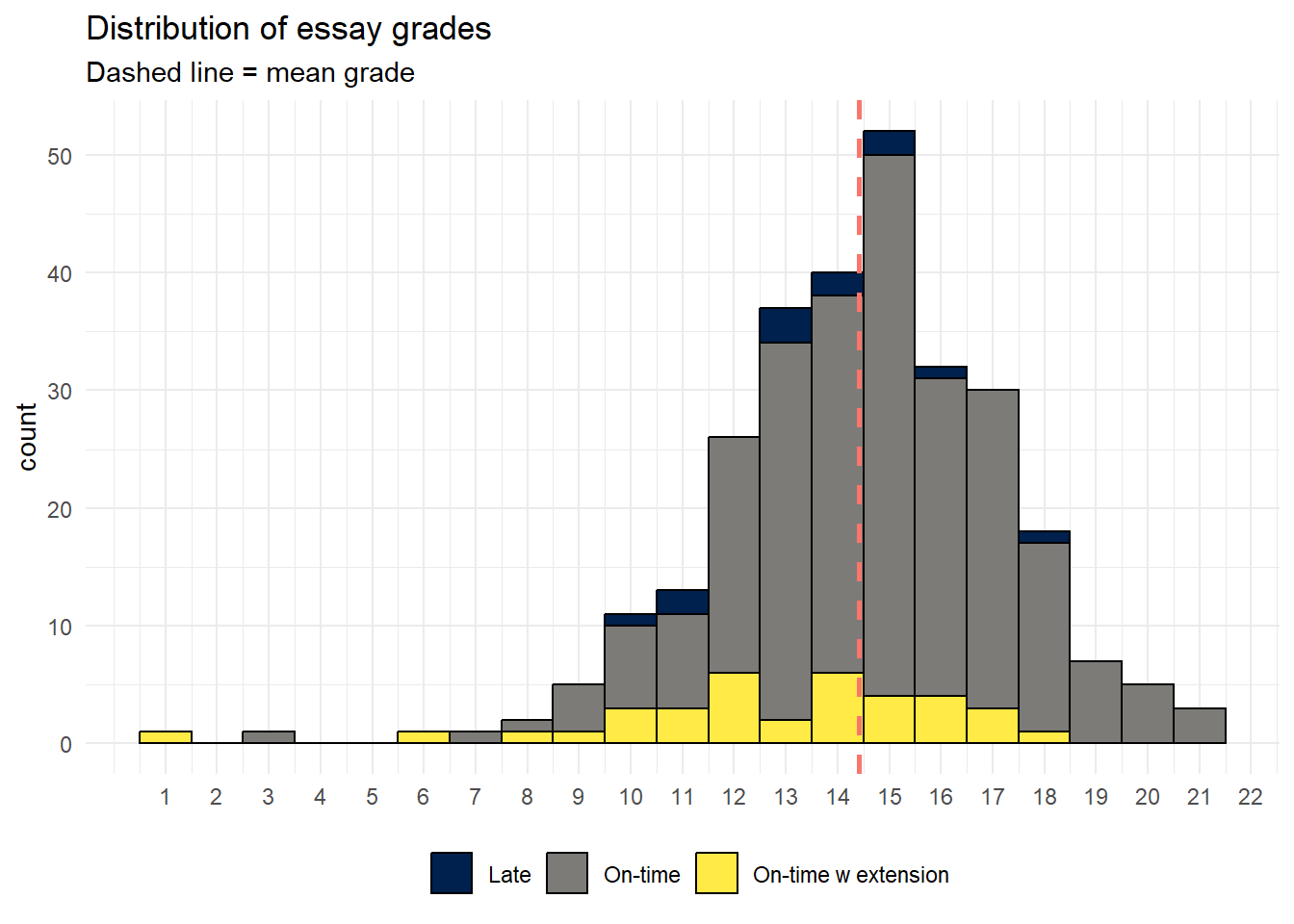
Or the descriptives by category:
dat_cleaned %>%
group_by(submission_category) %>%
summarise(mean_grade = mean(Points, na.rm = TRUE),
median_grade = median(Points, na.rm = TRUE))| submission_category | mean_grade | median_grade |
|---|---|---|
| Late | 13.58333 | 13.5 |
| On-time | 14.68776 | 15.0 |
| On-time w extension | 12.83333 | 13.5 |
With an associated visualization:
ggplot(dat_cleaned, aes(x = submission_category, y = Points, fill = submission_category)) +
geom_violin(show.legend = FALSE,
alpha = .4) +
geom_boxplot(width = .2, show.legend = FALSE) +
theme_minimal() +
scale_fill_viridis_d(option = "E") +
labs(x = NULL, title = "Grade point by submission category")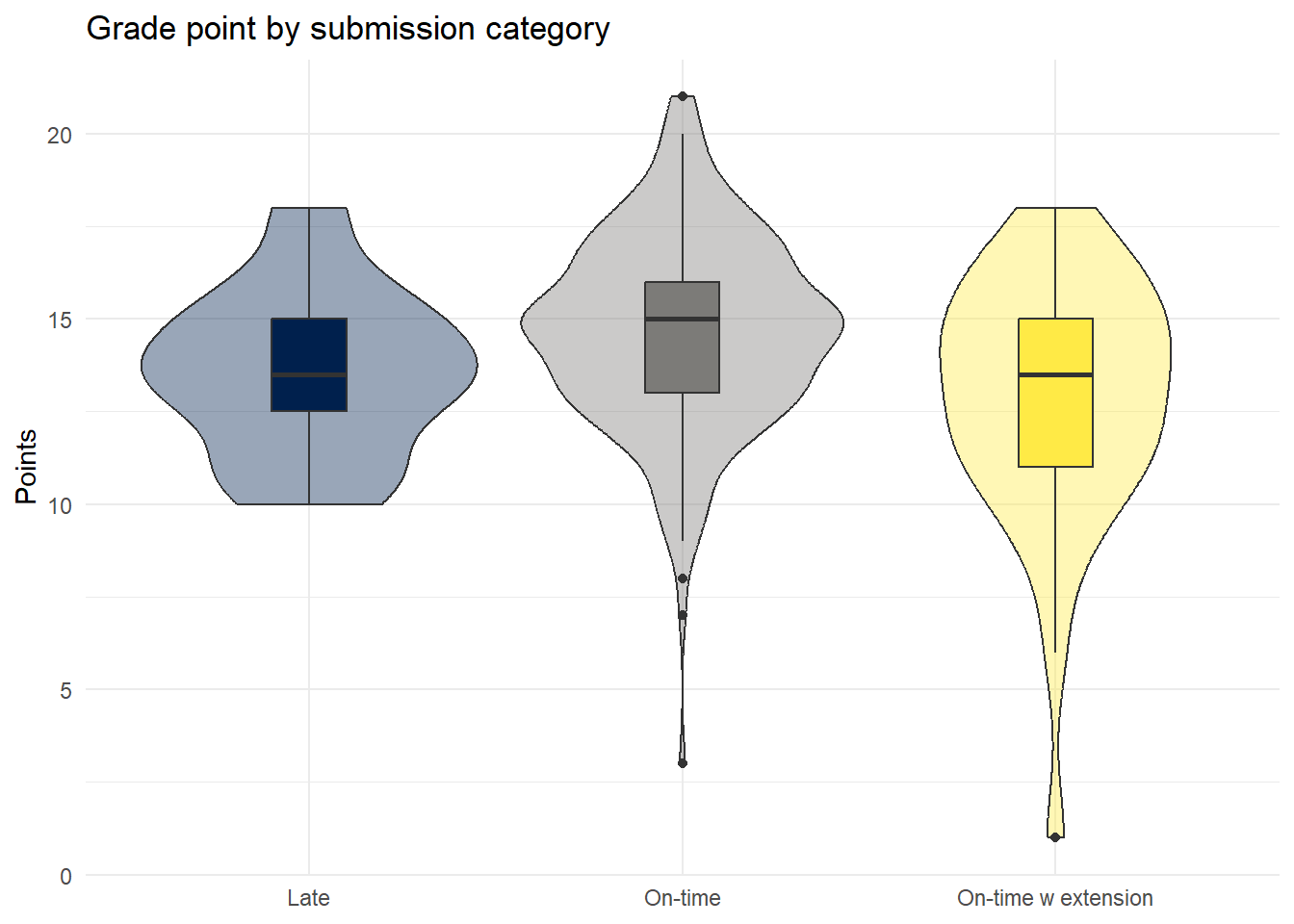
The correlation between Turnitin score and grade (even with real data I think this would be a bit pointless but you never know):
ggplot(dat_cleaned, aes(Points, Turnitin)) +
geom_jitter() + # use jitter rather than geom_point as some overlapping data points
geom_smooth(method = "loess") + # no clear linear relationship, otherwise use method = "lm"
labs(x = "Grade point", y = "Turnitin score")## `geom_smooth()` using formula = 'y ~ x'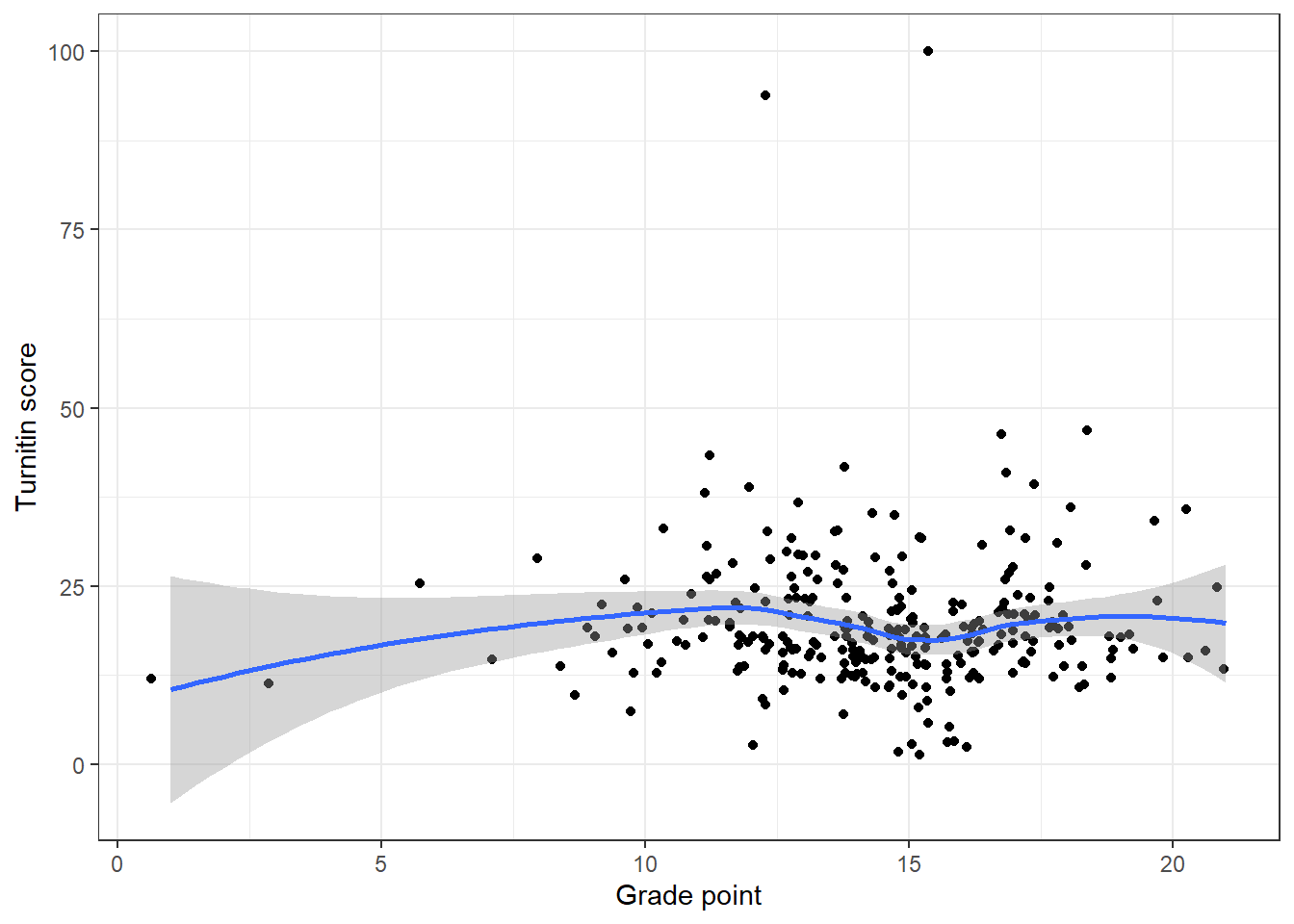
The relationship between Turnitin score and submission category - this code removes the two outliers - remove the filter line to put them back in.
dat_cleaned %>%
filter(Turnitin < 75) %>%
group_by(submission_category) %>%
summarise(mean_grade = mean(Turnitin, na.rm = TRUE),
median_grade = median(Turnitin, na.rm = TRUE))| submission_category | mean_grade | median_grade |
|---|---|---|
| Late | 19.50000 | 18 |
| On-time | 19.00847 | 18 |
| On-time w extension | 19.85714 | 18 |
With an associated visualisation:
dat_cleaned %>%
filter(Turnitin < 75) %>%
ggplot(aes(x = submission_category, y = Turnitin, fill = submission_category)) +
geom_violin(show.legend = FALSE,
alpha = .4) +
geom_boxplot(width = .2, show.legend = FALSE) +
theme_minimal() +
scale_fill_viridis_d(option = "E") +
labs(x = NULL, title = "Turnitin score by submission category")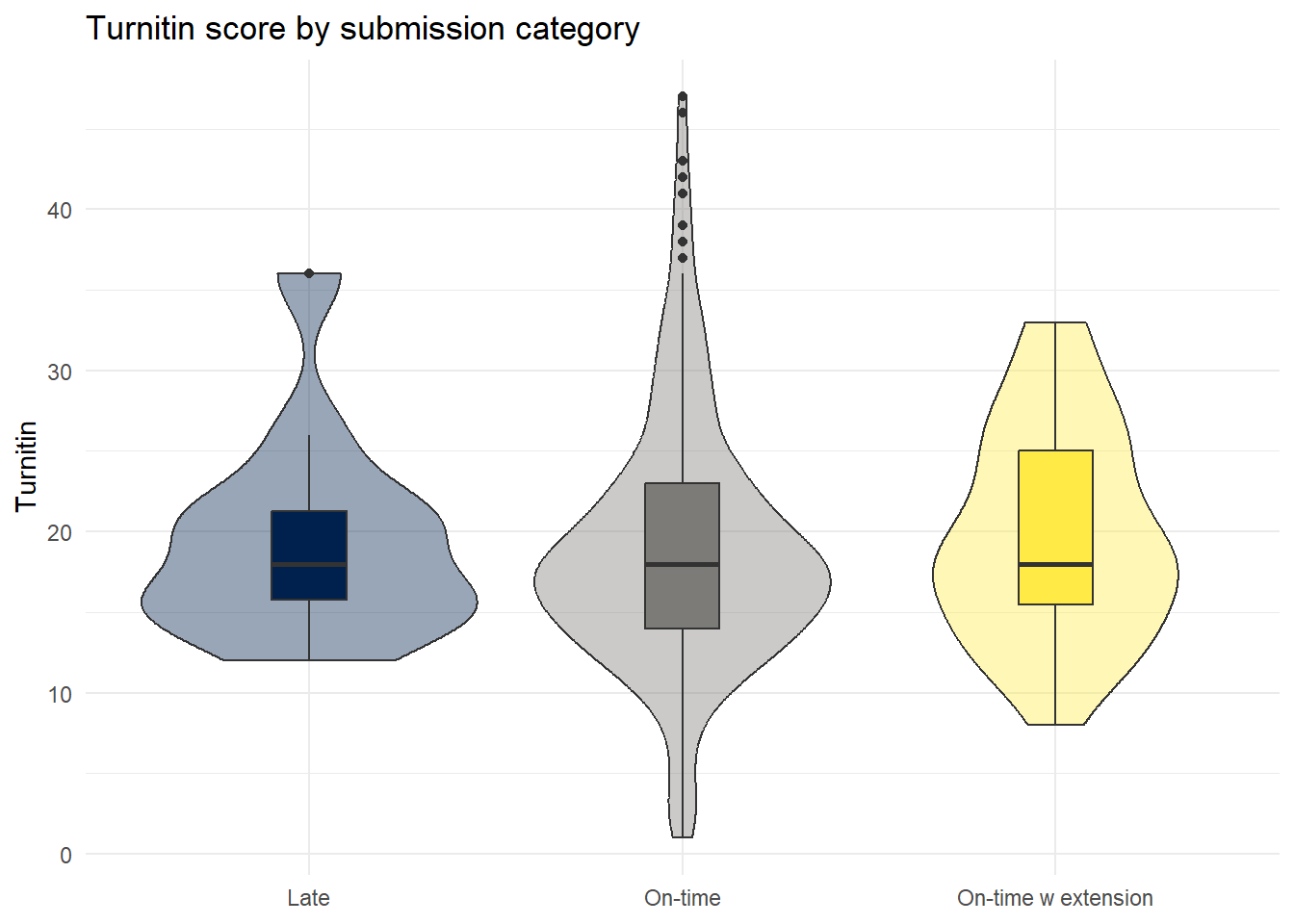
Finally, we could also look at grades by marker:
dat_cleaned %>%
group_by(Grader) %>%
summarise(mean_grade = mean(Points, na.rm = TRUE),
median_grade = median(Points, na.rm = TRUE))| Grader | mean_grade | median_grade |
|---|---|---|
| Marker 1 | 13.78082 | 14 |
| Marker 2 | 14.98592 | 15 |
| Marker 3 | 14.67143 | 15 |
| Marker 4 | 14.21127 | 14 |
Violin-boxplots:
dat_cleaned %>%
ggplot(aes(x = Grader, y = Points, fill = Grader)) +
geom_violin(show.legend = FALSE,
alpha = .4) +
geom_boxplot(width = .2, show.legend = FALSE) +
theme_minimal() +
scale_fill_viridis_d(option = "E") +
labs(x = NULL, title = "Grade point by marker")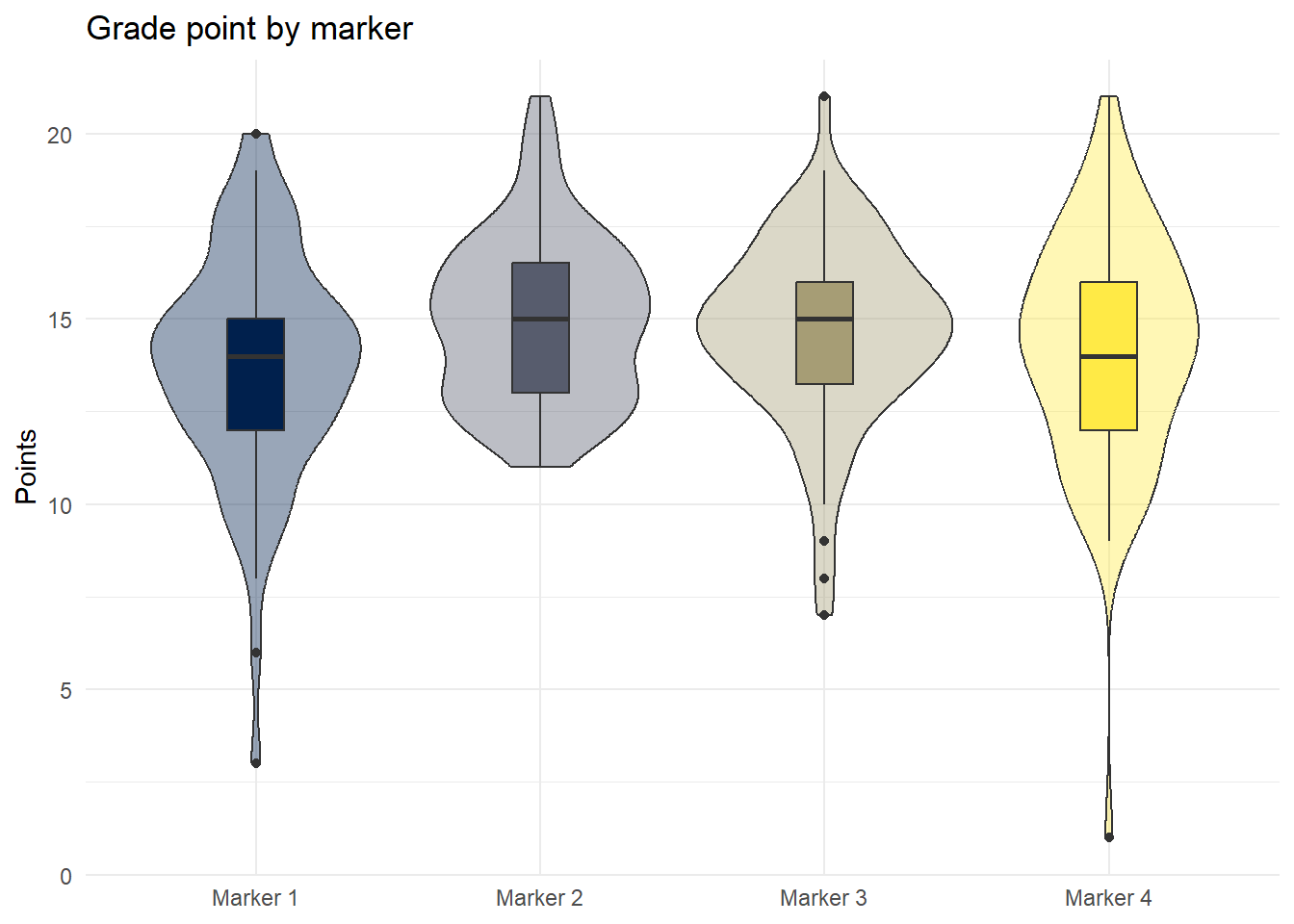
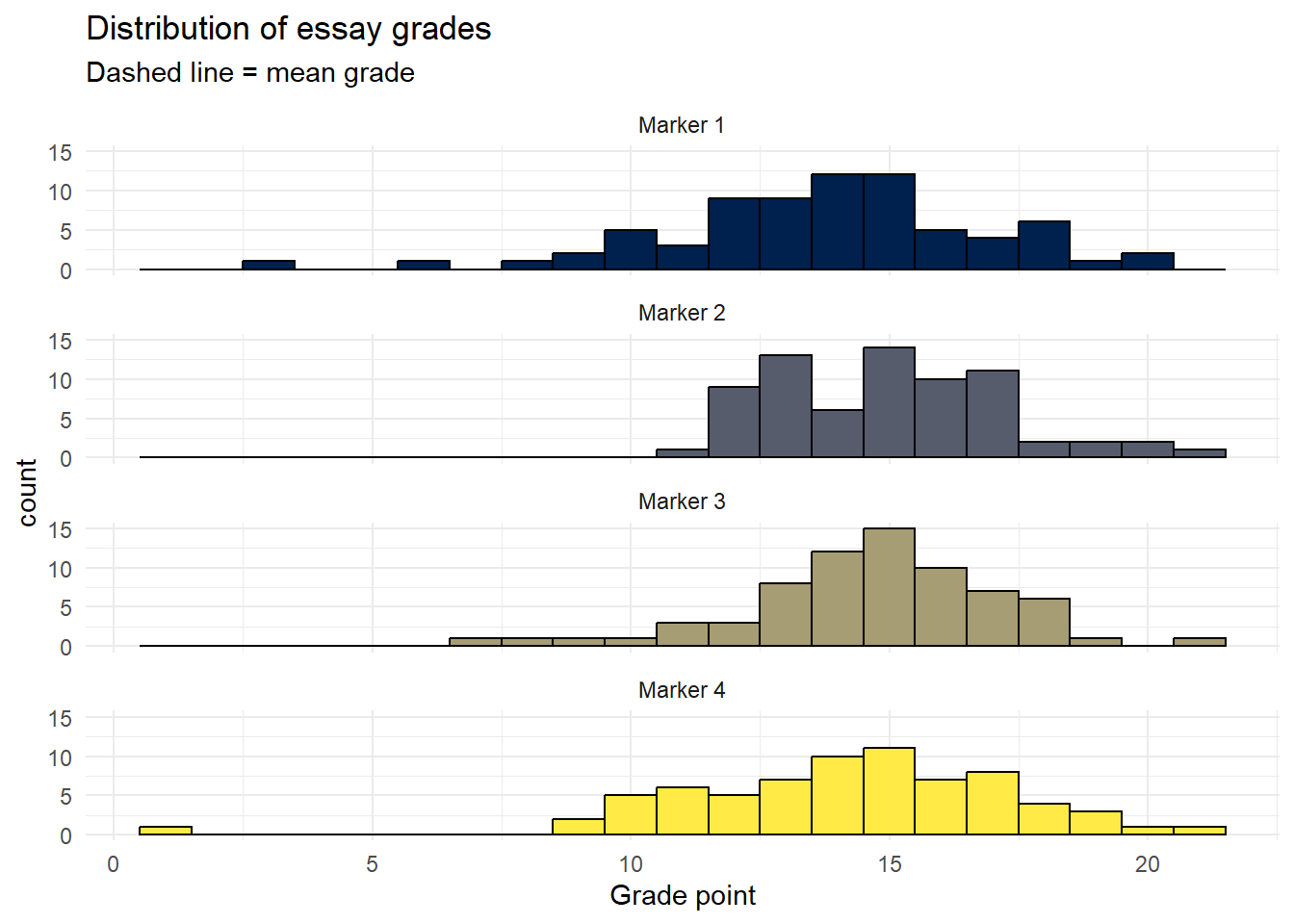
Finally, rather than using grouped histograms as we've done previously, it's better to visualise the distributions of different markers using facet_wrap() as it makes it easier to compare the distributions:
ggplot(dat_cleaned, aes(Points, fill = Grader)) +
geom_histogram(binwidth = 1, colour = "black", show.legend = FALSE) +
theme_minimal() +
labs(title = "Distribution of essay grades",
x = "Grade point",
subtitle = "Dashed line = mean grade",
fill = NULL) +
theme(legend.position = "bottom") +
scale_fill_viridis_d(option = "E") +
facet_wrap(~Grader, nrow = 4)