3 Section 1
3.1 Organising a project
Before we write any code, first, we need to get organised. Projects in RStudio are a way to group all the files you need for one project. Most projects include scripts, data files, and output files like the PDF report created by the script or images.
The folder that R will look in by default to find and save files is known as the working directory. You can set the working directory manually to the folder you want to work in with menu commands:
Session > Set Working Directory > Choose Directory...
However, there's a better way of organising your files by using Projects in RStudio.
3.1.1 Start a Project
To create a new project for this workshop:
File > New Project...- Name the project
workshop-dataviz - Save it somewhere sensible on your computer.
RStudio will restart itself and open with this new project directory as the working directory.
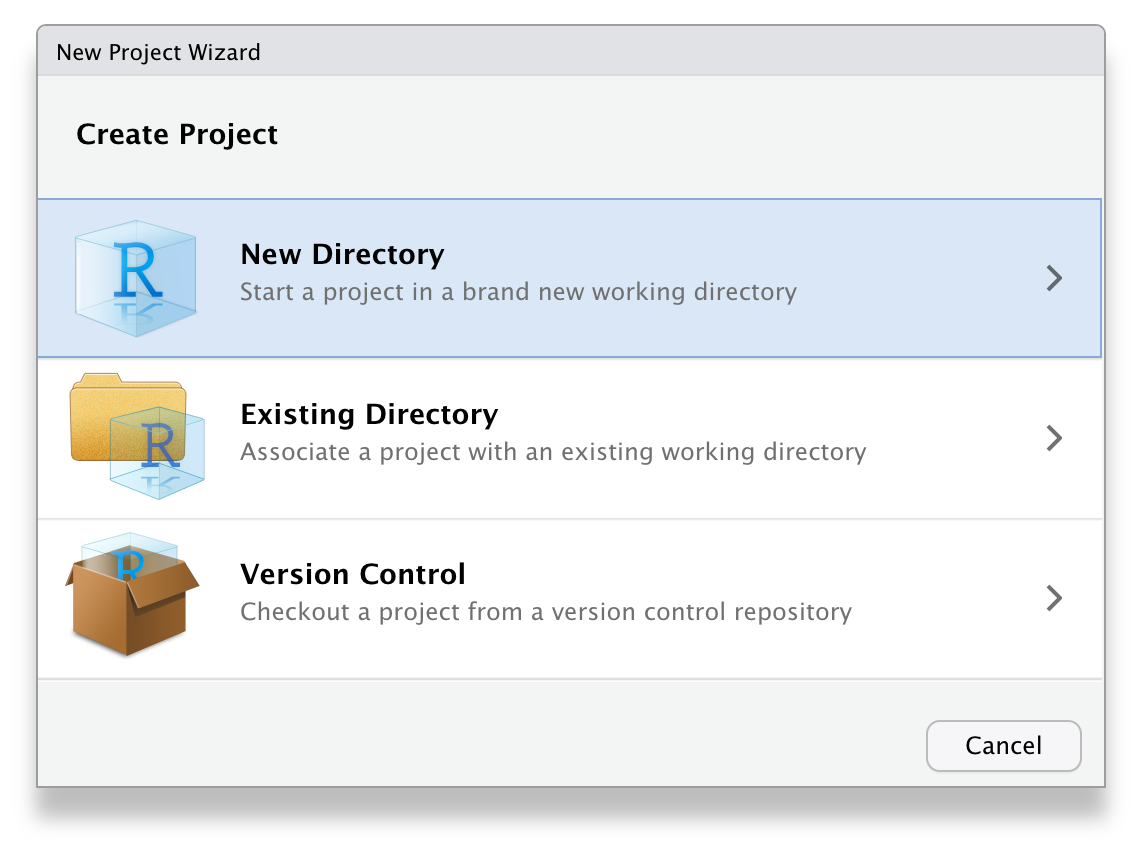
Figure 3.1: Starting a new project.
Click on the Files tab in the lower right pane to see the contents of the project directory. You will see a file called workshop-dataviz.Rproj, which is a file that contains all of the project information. You can double-click on it to open up the project.
Depending on your settings, you may also see a directory called .Rproj.user, which contains your specific user settings. You can ignore this and other "invisible" files that start with a full stop.
3.2 R Markdown
For this workshop we will use R Markdown. We won't have time to cover too many of the features of R Markdown but it's an incredibly powerful format that allows you to create fully reproducible reports where all text, code, and analysis is contained within the one document. You can also use it to create websites, online books (like this one), presentations, and Shiny apps. If you'd like to learn more about R Markdown, there's links to additional resources in Section 3.11.
3.2.1 New document
To open a new R Markdown document click:
File > New File > R Markdown
You will be prompted to give it a title; call the document Day 1. You can also change the author name. Keep the output format as HTML.
Once you've opened a new document be sure to save it by clicking File > Save As.... You should name this file section_1 (if you are on a Mac and can see the file extension, name it section_1.Rmd). This file will automatically be saved in your project folder, i.e., your working directory, so you should now see this file appear in your file viewer pane.
When you first open a new R Markdown document you will see a bunch of welcome text that looks like this:
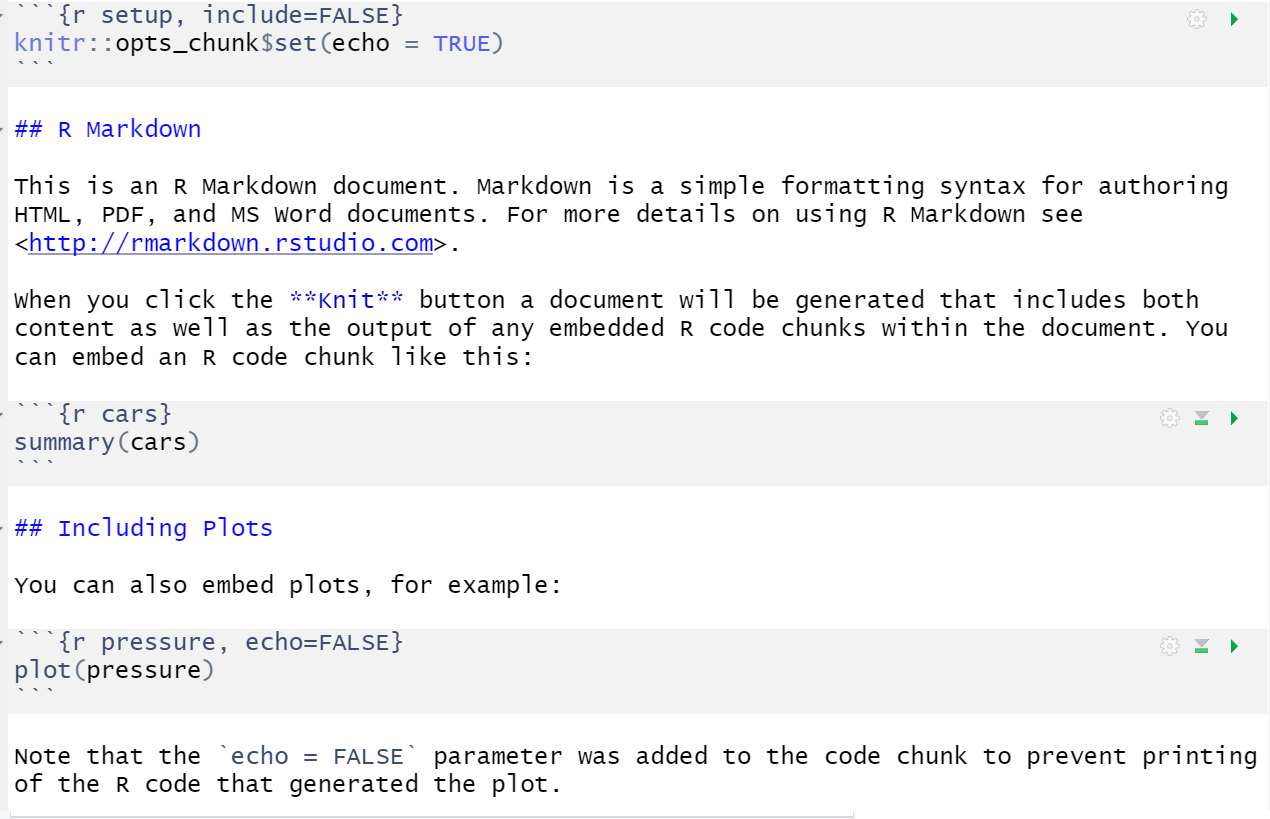
Figure 3.2: New R Markdown text
Do the following steps:
- Change the title to "Data viz section 1" and the author to your name
- Delete everything after the setup chunk
- Skip a line after the setup chunk and type "## Set-up" (with the hashes but without the quotation marks); make sure there are no spaces before the hashes and at least one space after the hashes before the subtitle
- Skip a line and click the insert new code menu (a green box with a C and a plus sign) then
R
3.2.2 Code chunks
What you have created is a subtitle and a code chunk. In R Markdown, anything written in a grey code chunk is assumed to be code, and anything written in the white space (between the code chunks) is regarded as normal text (the actual colours will depend on which theme you have applied, but we will refer to the default white and grey). This makes it easy to combine both text and code in one document.
When you create a new code chunk you should notice that the grey box starts and ends with three back ticks ```. One common mistake is to accidentally delete these back ticks. Remember, code chunks and text entry are different colours - if the colour of certain parts of your Markdown doesn't look right, check that you haven't deleted the back ticks.
In your code chunk, write the code to load the packages that you installed in the prep work.
3.2.3 Running code
When you're working in an R Markdown document, there are several ways to run your lines of code.
First, you can highlight the code you want to run and then click
Run->Run Selected Line(s), however this is tedious and can cause problems if you don't highlight exactly the code you want to run.Alternatively, you can press the green "play" button at the top-right of the code chunk and this will run all lines of code in that chunk.
Even better is to learn some of the keyboard short cuts for R Studio. To run a single line of code, make sure that the cursor is in the line of code you want to run (it can be anywhere) and press
ctrl + enterorCmd + enterif you're on a Mac. If you want to run all of the code in the code chunk, pressctrl/cmd + shift + enter. Learn these short cuts, they will make your life easier!
Run your code using method 3. You should see the packages load in the console.
3.3 Loading data
Broadly speaking there are three types of data you can load when working in R:
- Built-in data sets that come with the packages you install that are useful for reproducible demos. Common ones you will see when you Google help documentation are
mtcarsanddiamonds. - Data sets stored online and accessed via a URL.
- Data sets stored locally on your computer.
For this section we'll use 1 and 2 and in section 2 we'll use 3.
3.3.1 Built-in data
The data() function lists the data sets available.
# list datasets built in to base R
data()
# lists datasets in a specific package
data(package = "dplyr")Type the name of a data set into the console to see the data. For example, type ?starwars into the console to see the dataset description for starwars, which is a data set included with dplyr.
?starwarsYou can also use the data() function to load a dataset into your global environment.
# loads starwars into the environment
data("starwars")You can now use this data. Insert a new heading (##) named "My first plot". The underneath it, create a new code chunk, and copy, paste, and run the below code. You may not understand this yet, but you will by the end of the session.
ggplot(starwars, aes(x = mass)) +
geom_histogram(colour = "black") +
theme_economist() +
labs(title = "Mass of Star Wars characters",
subtitle = "Original trilogy")3.3.2 Online sources
Now, let's try loading data that is stored online. Create a code chunk in your document and copy, paste, and run the below code. This code loads some simulated customer satisfaction data.
- The data is stored in a
.csvfile so we're going to use theread_csv()function to load it in. - Note that the url is contained within double quotation marks - it won't work without this.
survey_data <- read_csv("https://psyteachr.github.io/ads-v1/data/survey_data.csv")If you get an error message that looks like:
Error in read_csv("https://psyteachr.github.io/ads-v1/data/survey_data.csv") :
could not find function "read_csv"
This means that you have not loaded tidyverse. Check that library(tidyverse) is in the setup chunk and that you have run the setup chunk.
This data is simulated data for a call centre customer satisfaction survey. The first thing you should do when you need to plot data is to get familiar with what all of the rows (observations) and columns (variables) mean. Sometimes this is obvious, and sometimes it requires help from the data provider. Here, each row represents one call to the centre.
-
caller_idis a unique ID for each caller -
employee_idis a unique ID for each employee taking calls -
call_startis the date and time that the call arrived -
wait_timeis the number of seconds the caller had to wait -
call_timeis the number of seconds the call lasted after the employee picked up -
issue_categoryis whether the issue was tech, sales, returns, or other -
satisfactionis the customer satisfaction rating on a scale from 1 (very unsatisfied) to 5 (very satisfied)
Create another heading (##) named "My second plot", another code chunk below it, and copy, paste, and run the code below.
ggplot(survey_data, aes(x = call_time)) +
geom_histogram(colour = "black", fill = "wheat") +
theme_excel() +
labs(x = "Time spent on call (seconds)",
title = "Customer calls")3.4 Knitting your file
Before we move on to focus on visualisation, we are going to knit, or compile, the file into a document type of our choosing. To knit your file click:
Knit > Knit to HMTL
R Markdown will create and display a new HTML document, but it will also automatically save this file in your working directory.
You can also knit by typing the following code into the console. Never put this in an Rmd script itself, or it will try to knit itself in an infinite loop.
We don't have time to cover how to customise the knitted output in this workshop, but suffice to say that you can control almost every aspect, from whether the code is displayed or hidden, to the size and placement of the figures.
As you work through this workshop, we encourage you to use the Markdown document to take notes on the code and the output you create so that you have a complete single record of the work you've done. In particular, use headings and new code chunks to separate tasks, and if (when) you experience an error, make a note of how you fixed it.
Ok, let's get started properly.
3.5 Building plots
There are multiple approaches to data visualisation in R; in this workshop we will use the popular package ggplot2, which is part of the larger tidyverse collection of packages. A grammar of graphics (the "gg" in "ggplot") is a standardised way to describe the components of a graphic. ggplot2 uses a layered grammar of graphics, in which plots are built up in a series of layers. It may be helpful to think about any picture as having multiple elements that sit semi-transparently over each other. A good analogy is old Disney movies where artists would create a background and then add moveable elements on top of the background via transparencies.
Figure 3.3 displays the evolution of a simple scatterplot using this layered approach. First, the plot space is built (layer 1); the variables are specified (layer 2); the type of visualisation (known as a geom) that is desired for these variables is specified (layer 3) - in this case geom_point() is called to visualise individual data points; a second geom is added to include a line of best fit (layer 4), the axis labels are edited for readability (layer 5), and finally, a theme is applied to change the overall appearance of the plot (layer 6).
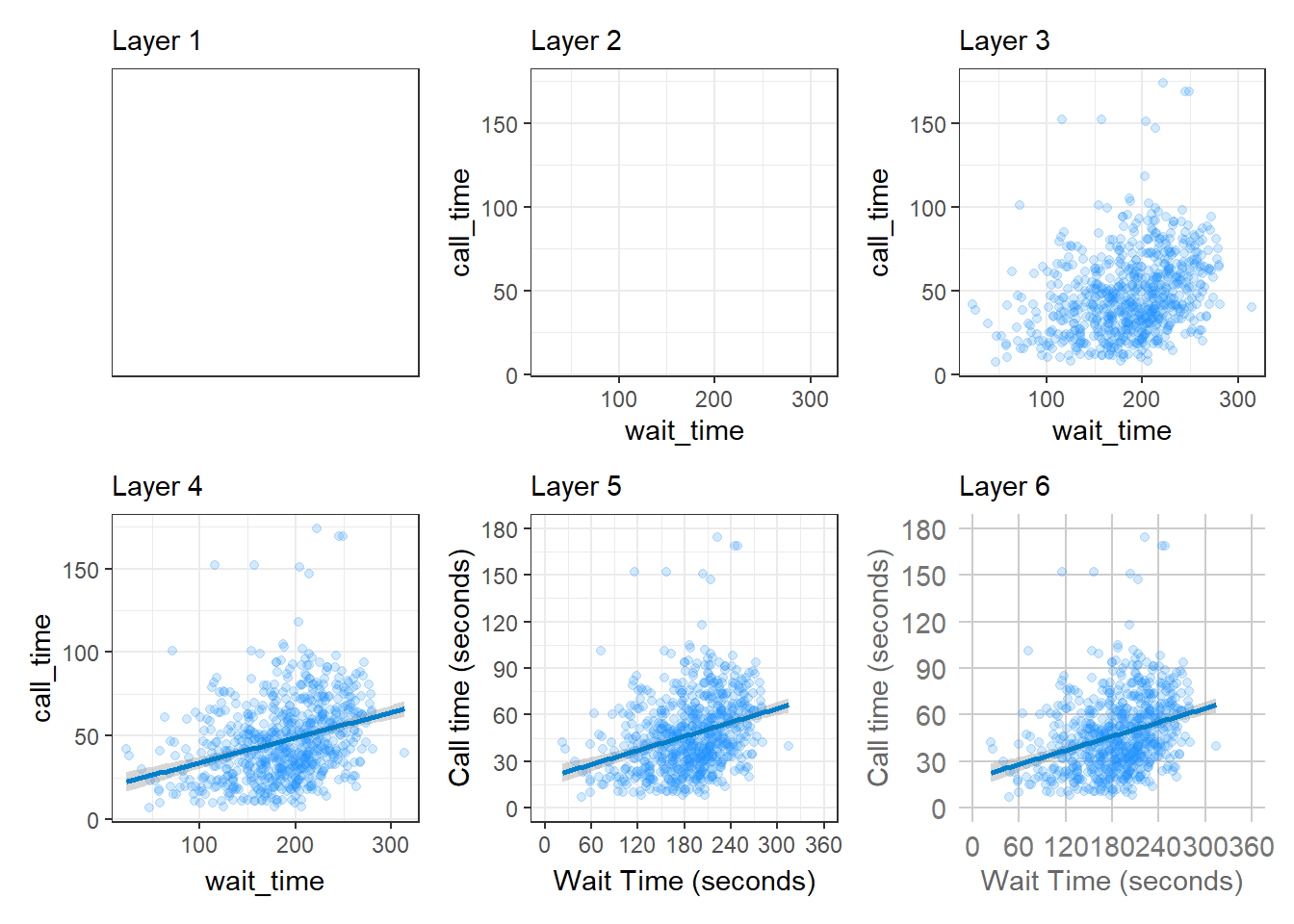
Figure 3.3: Evolution of a layered plot
Importantly, each layer is independent and independently customisable. For example, the size, colour and position of each component can be adjusted, or one could, for example, remove the first geom (the data points) to only visualise the line of best fit, simply by removing the layer that draws the data points (Figure 3.4). The use of layers makes it easy to build up complex plots step-by-step, and to adapt or extend plots from existing code.
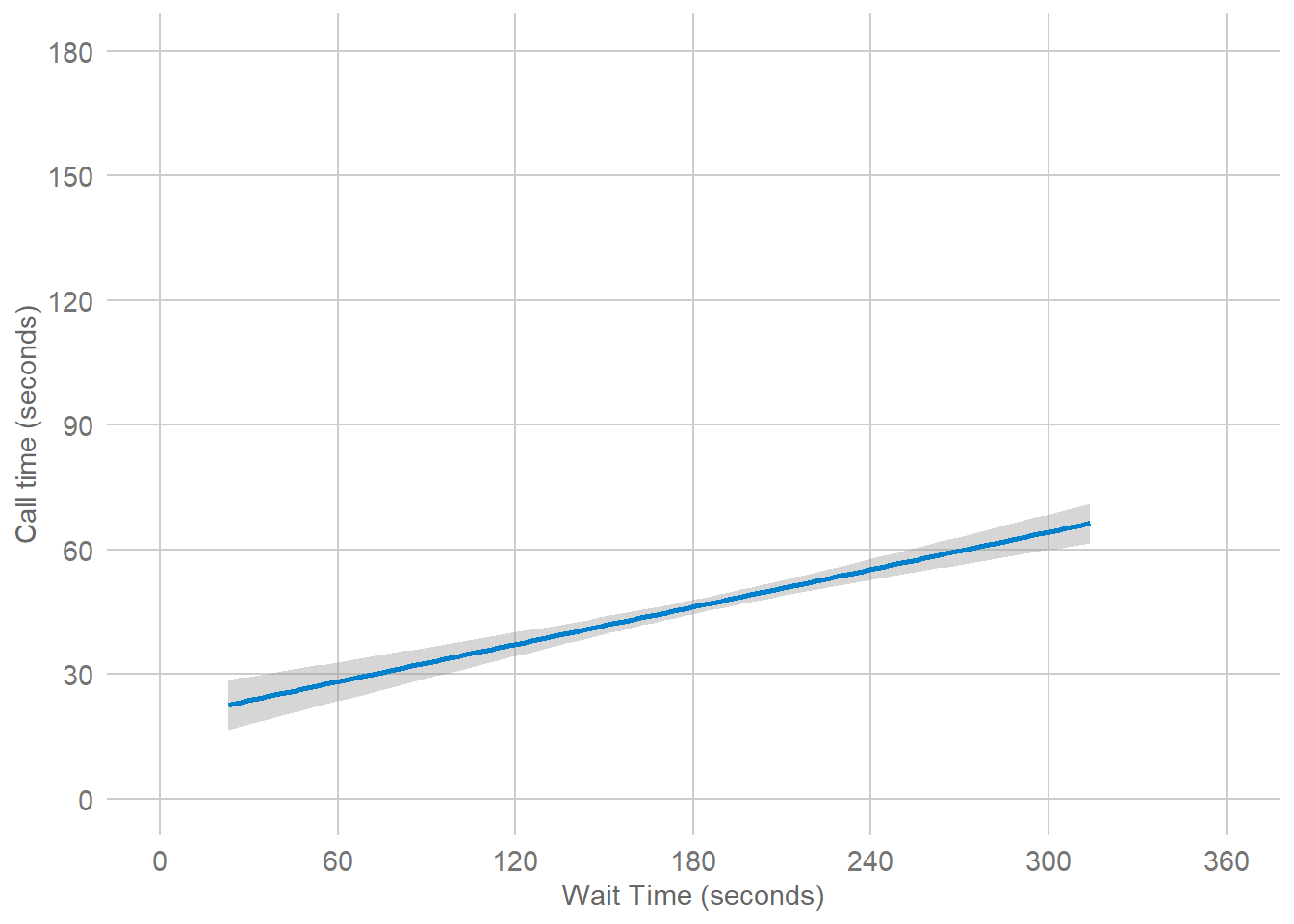
Figure 3.4: Final plot with scatterplot layer removed.
3.6 Plot setup
3.6.1 Data
Every plot starts with the ggplot() function and a data table. If your data are not loaded or you have a typo in your code, this will give you an error message. It's best to check your plot after each step, so that you can figure out where errors are more easily.
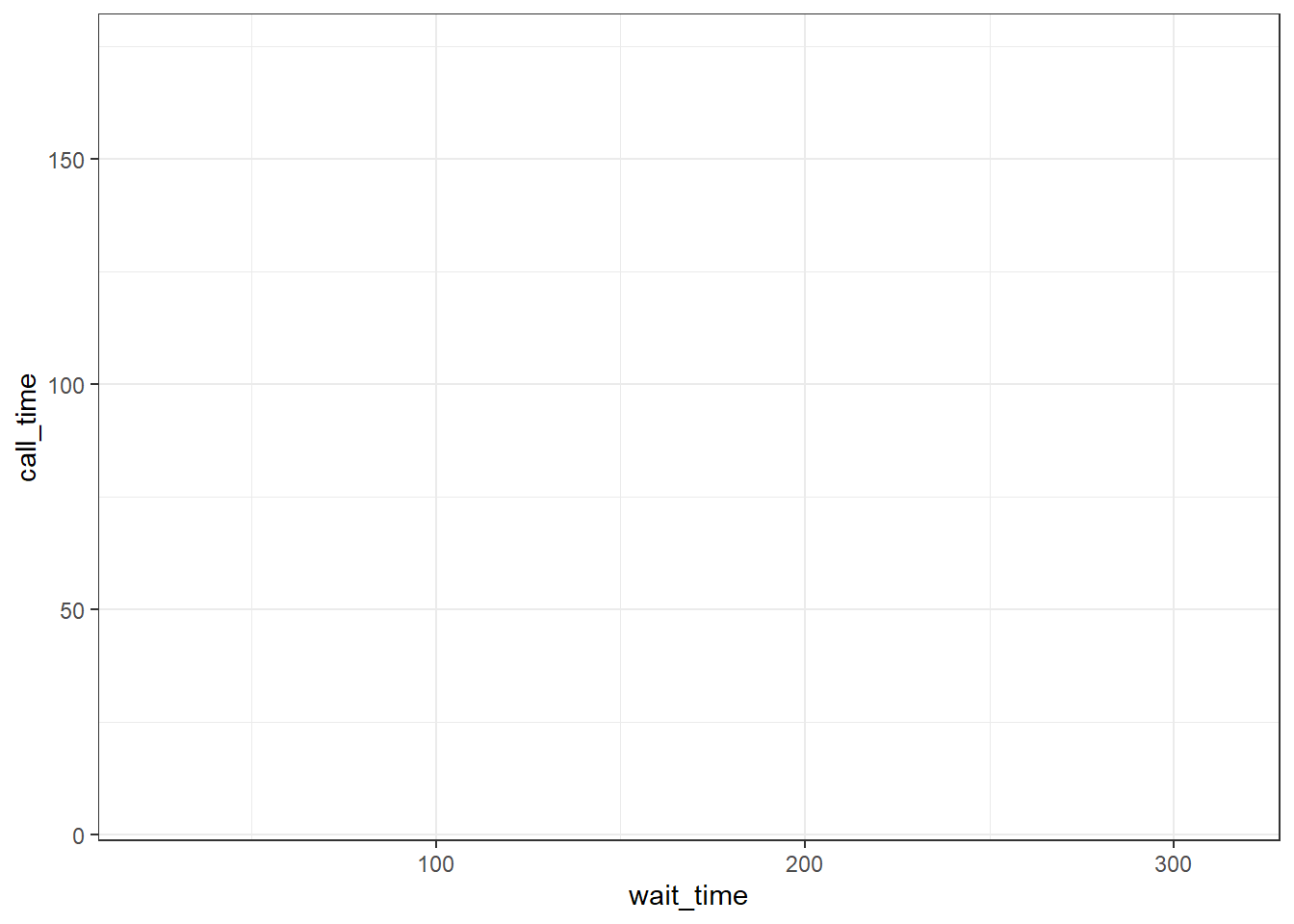
ggplot(data = survey_data)
Figure 3.5: A blank ggplot.
3.6.2 Mapping
The next argument to ggplot() is the mapping. This tells the plot which columns in the data should be represented by, or "mapped" to, different aspects of the plot, such as the x-axis, y-axis, line colour, object fill, or line style. These aspects, or "aesthetics", are listing inside the aes() function.
Set the arguments x and y to the names of the columns you want to be plotted on those axes. Here, we want to plot the wait time on the x-axis and the call time on the y-axis.
# set up the plot with mapping
ggplot(
data = survey_data,
mapping = aes(x = wait_time, y = call_time)
)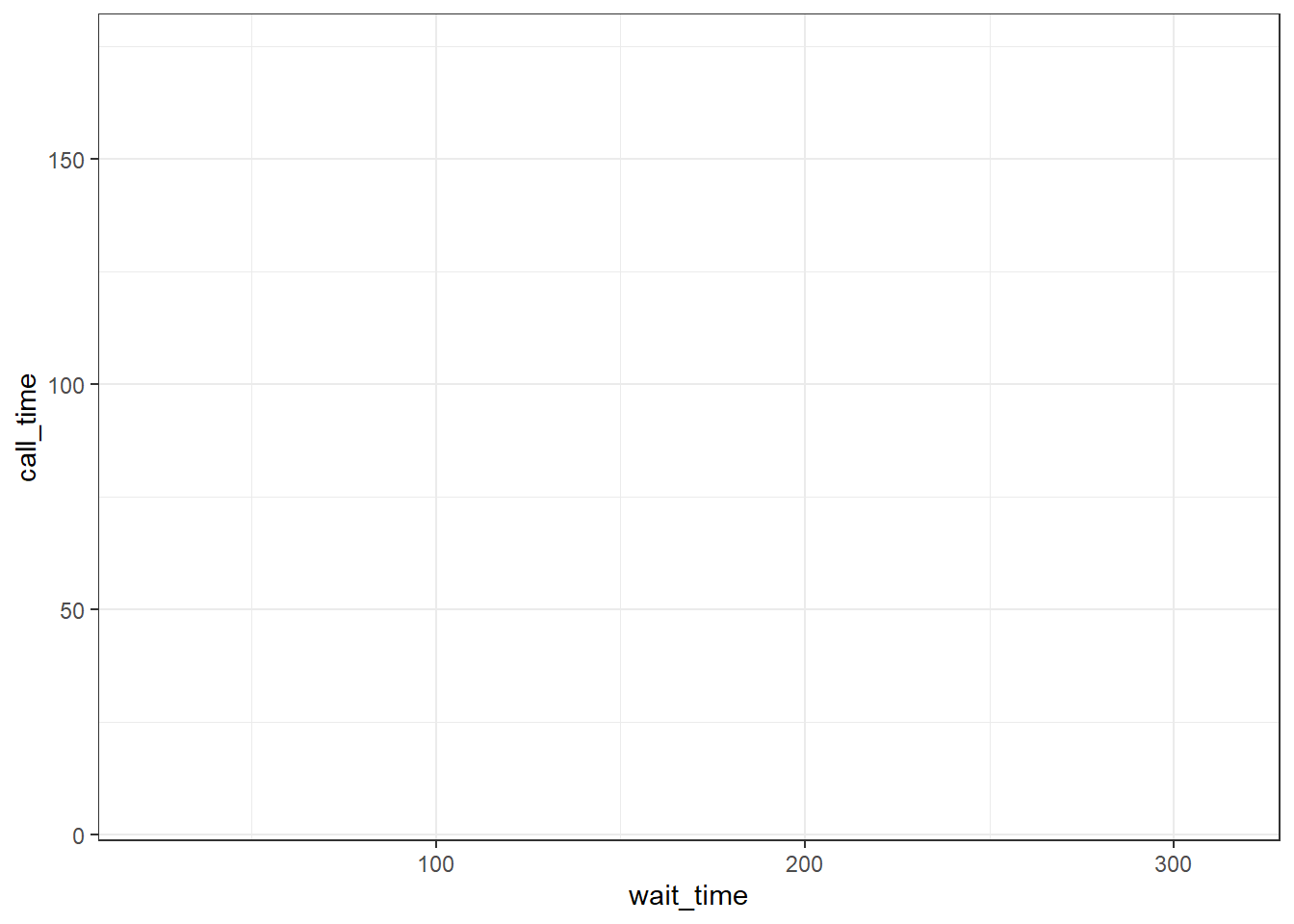
Figure 3.6: A blank plot with x- and y- axes mapped.
3.6.3 Geoms
Now we can add our plot elements in layers. These are referred to as geoms and their functions start with geom_. You add layers onto the base plot created by ggplot() with a plus (+).
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point() # scatterplot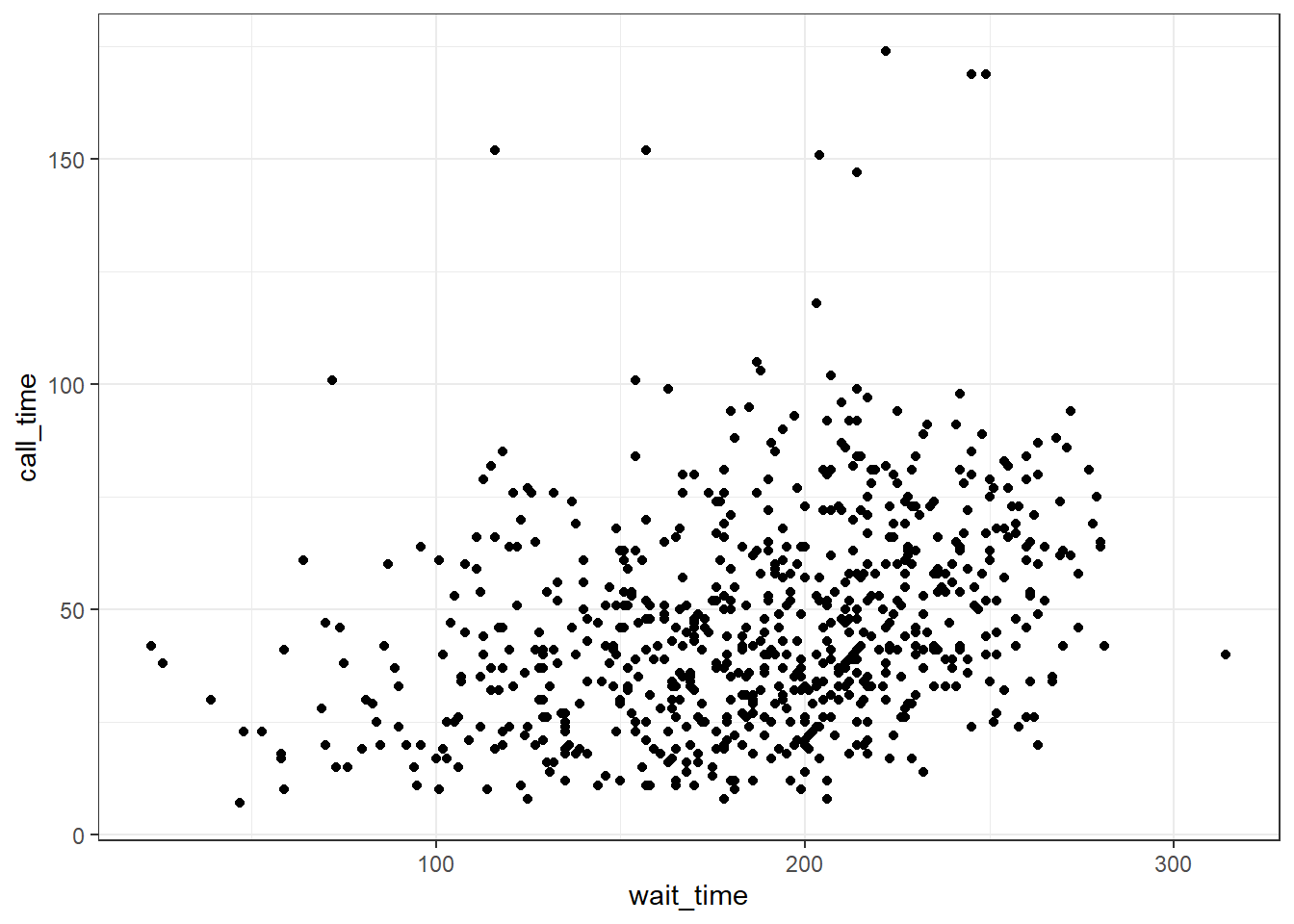
Figure 3.7: Adding a scatterplot with geom_point().
Somewhat annoyingly, the plus has to be on the end of the previous line, not at the start of the next line. If you do make this mistake, it will run the first line of code to produce the base layer but then you will get the following error message rather than adding on geom_point().
+ geom_point() # scatterplot## Error:
## ! Cannot use `+` with a single argument
## ℹ Did you accidentally put `+` on a new line?3.6.4 Multiple geoms
Part of the power of ggplot2 is that you can add more than one geom to a plot by adding on extra layers and so it quickly becomes possible to make complex and informative visualisations. Importantly, the layers display in the order you set them up. The code below uses the same geoms to produce a scatterplot with a line of best fit but orders them differently.
# Points first
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point() + # scatterplot
geom_smooth(method = lm) # line of best fit
# Line first
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_smooth(method = lm) + # line of best fit
geom_point() # scatterplot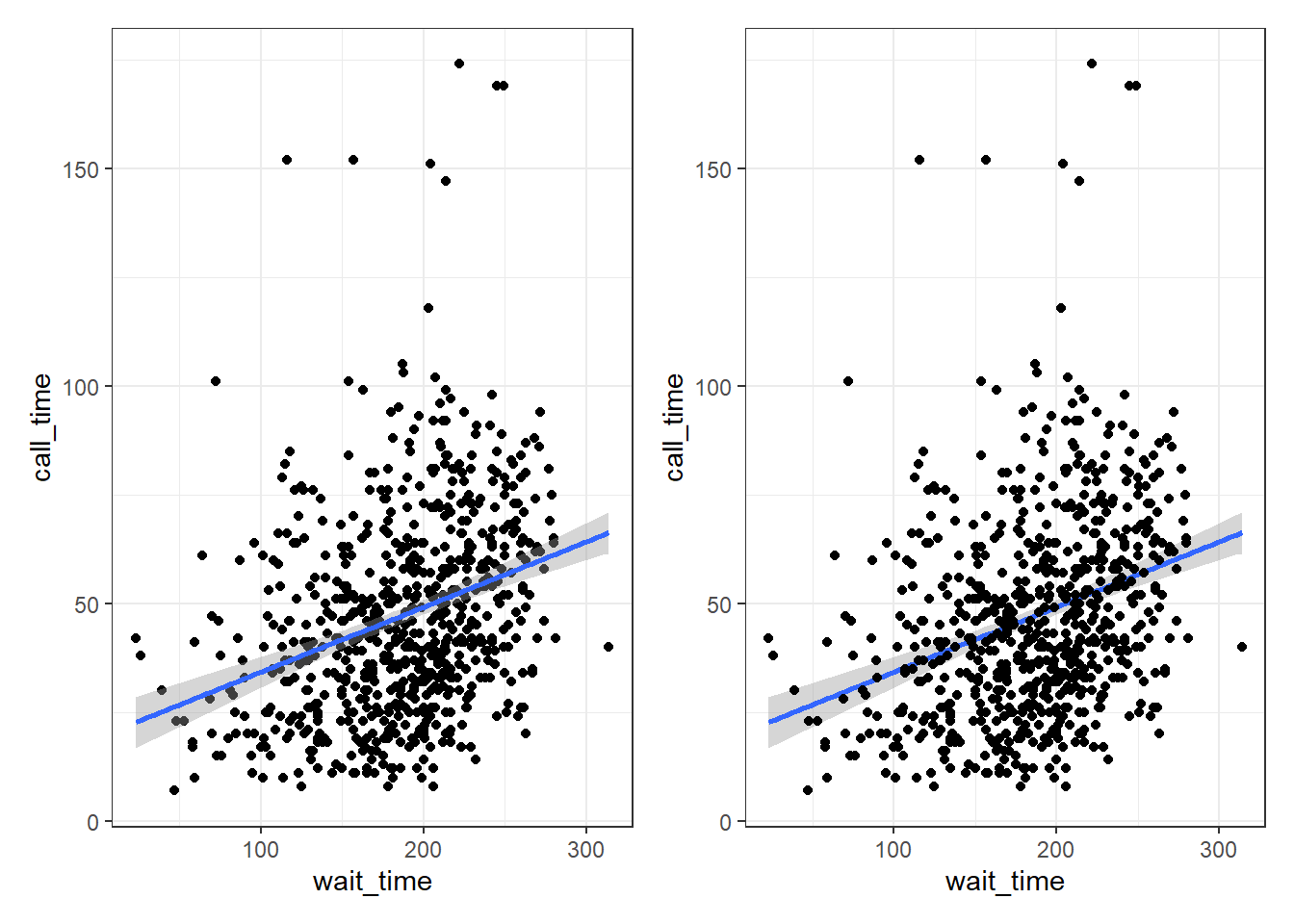
Figure 3.8: Points first versus line first.
3.6.5 Saving plots
Just like you can save numbers and data tables to objects, you can also save the output of ggplot(). The code below produces the same plots we created above but saves them to objects named point_first and line_first. If you run this code, the plots won't display like they have done before. Instead, you'll see the object names appear in the environment pane.
point_first <-
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point() + # scatterplot
geom_smooth(method = lm) # line of best fit
line_first <-
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_smooth(method = lm) + # line of best fit
geom_point() # scatterplotTo view the plots, call the objects by name. This will output each plot separately.
point_first # view first plot
line_first # view second plot3.6.6 Combining plots
One of the reasons to save your plots to objects is so that you can combine multiple plots using functions from the patchwork package. The below code produces the above plot by combining the two plots with + and then specifying that we want the plots produced on a single row with the nrow argument in plot_layout().
# add plots together in 1 row; try changing nrow to 2
point_first + line_first + plot_layout(nrow = 1)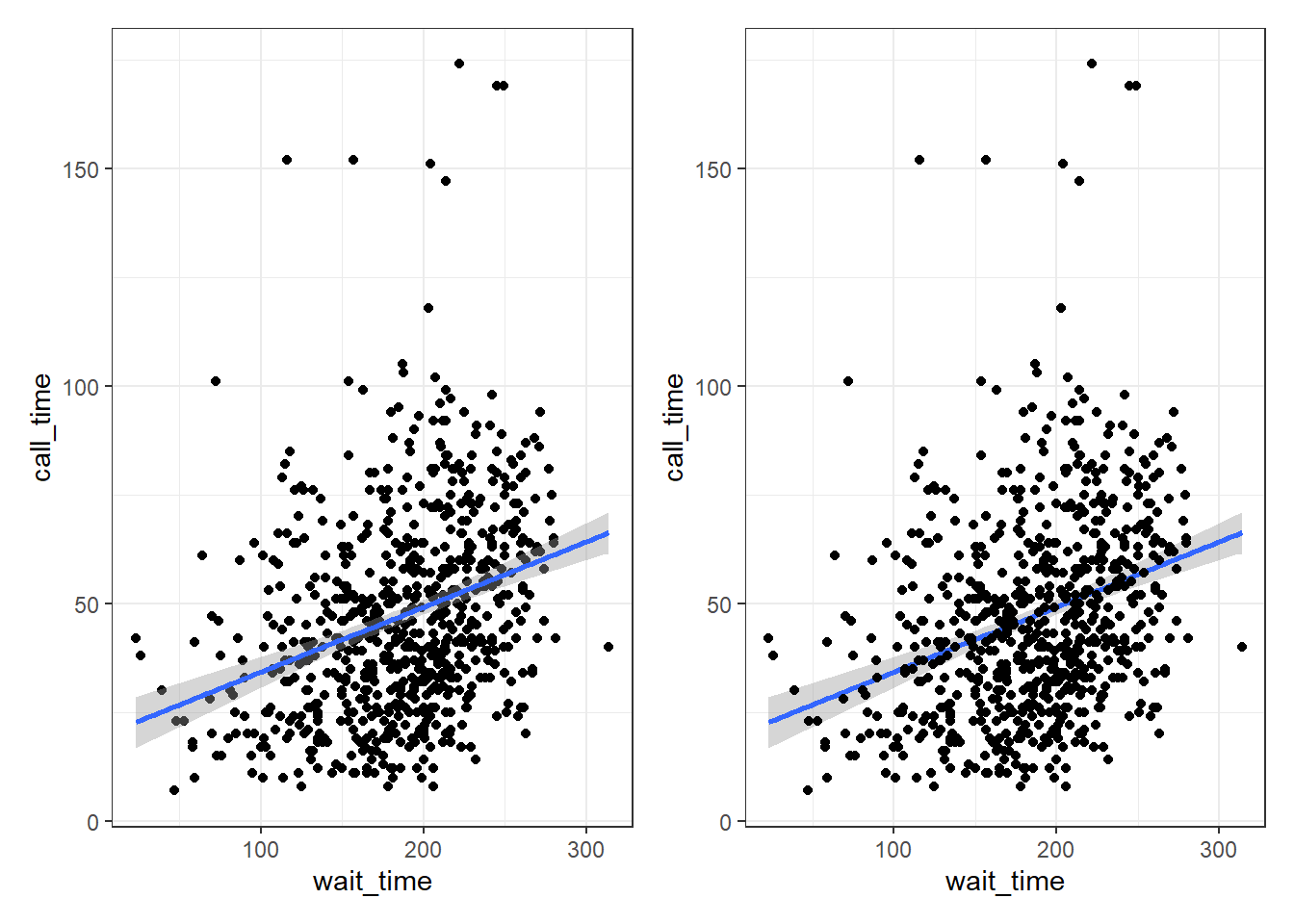
Figure 3.9: Combining plots with patchwork.
3.7 Customising plots
3.7.1 Format axes
Now we need to make the axes look neater. There are several functions you can use to change the axis labels, but the most powerful ones are the scale_ functions. You need to use a scale function that matches the data you're plotting on that axis and this is where it becomes particularly important to know what type of data you're working with. Both of the axes here are continuous, so we'll use scale_x_continuous() and scale_y_continuous().
The name argument changes the axis label. The breaks argument sets the major units and needs a vector of possible values, which can extend beyond the range of the data (e.g., wait time only goes up to 350, but we can specify breaks up to 600 in case we wanted to reuse our code with new data with different values). The seq() function creates a sequence of numbers from one to another by specified steps.
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point(alpha = 0.2) +
geom_smooth(method = lm) +
scale_x_continuous(name = "Wait Time (seconds)",
breaks = seq(from = 0, to = 600, by = 60)) +
scale_y_continuous(name = "Call time (seconds)",
breaks = seq(from = 0, to = 600, by = 30))## `geom_smooth()` using formula = 'y ~ x'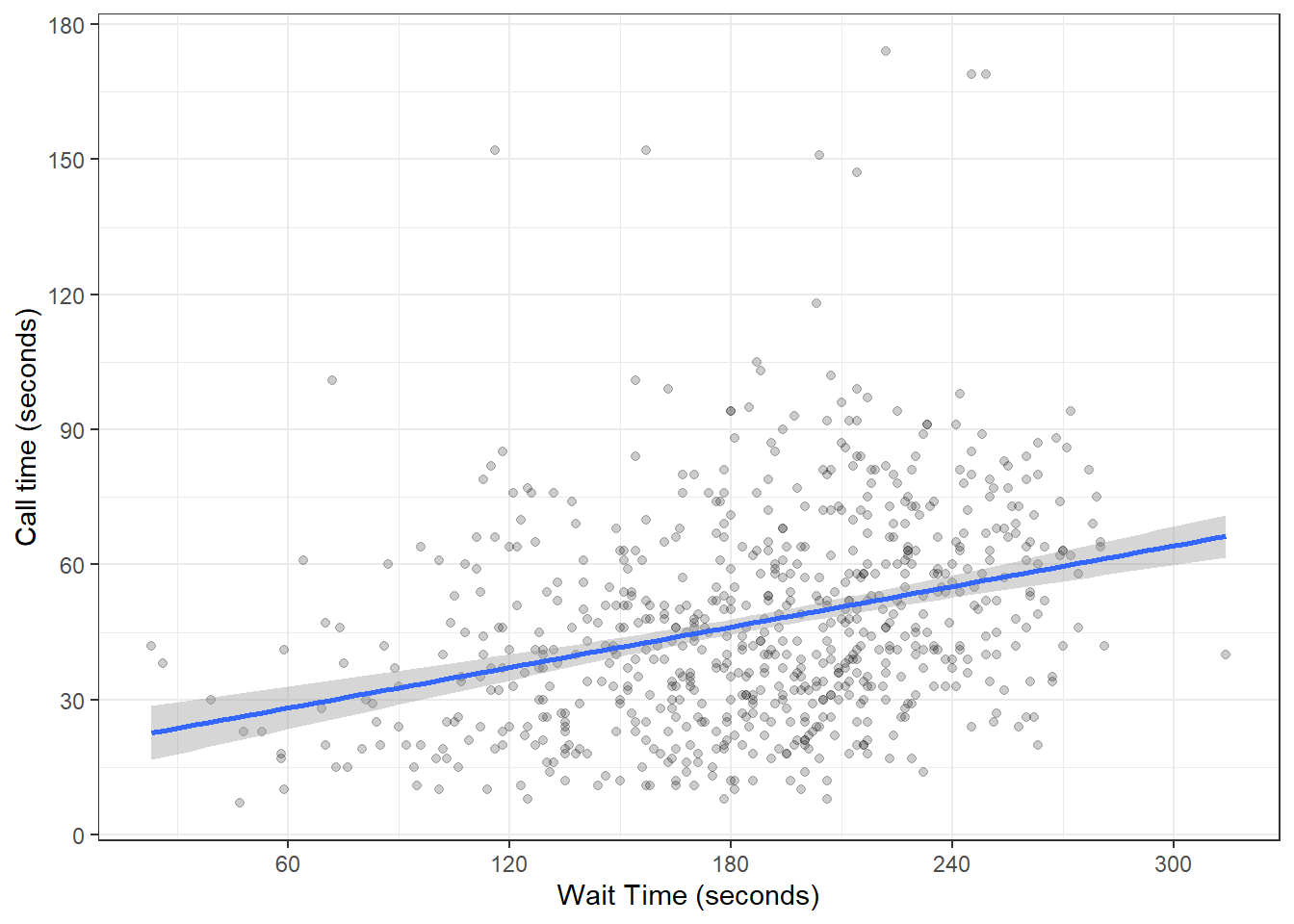
Figure 3.10: Formatting plot axes with scale_ functions.
Check the help for ?scale_x_continuous to see how you would set the minor units or specify how many breaks you want instead.
3.7.2 Axis limits
If you want to change the minimum and maximum values on an axis, use the coord_cartesian() function. Many plots make more sense if the minimum and maximum values represent the range of possible values, even if those values aren't present in the data. Here, wait and call times can't be less than 0 seconds, so we'll set the minimum values to 0 and the maximum values to the first break above the highest value.
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point(colour = "dodgerblue",
alpha = 0.2) +
geom_smooth(method = lm) +
scale_x_continuous(name = "Wait Time (seconds)",
breaks = seq(from = 0, to = 600, by = 60)) +
scale_y_continuous(name = "Call time (seconds)",
breaks = seq(from = 0, to = 600, by = 30)) +
coord_cartesian(xlim = c(0, 360),
ylim = c(0, 180))## `geom_smooth()` using formula = 'y ~ x'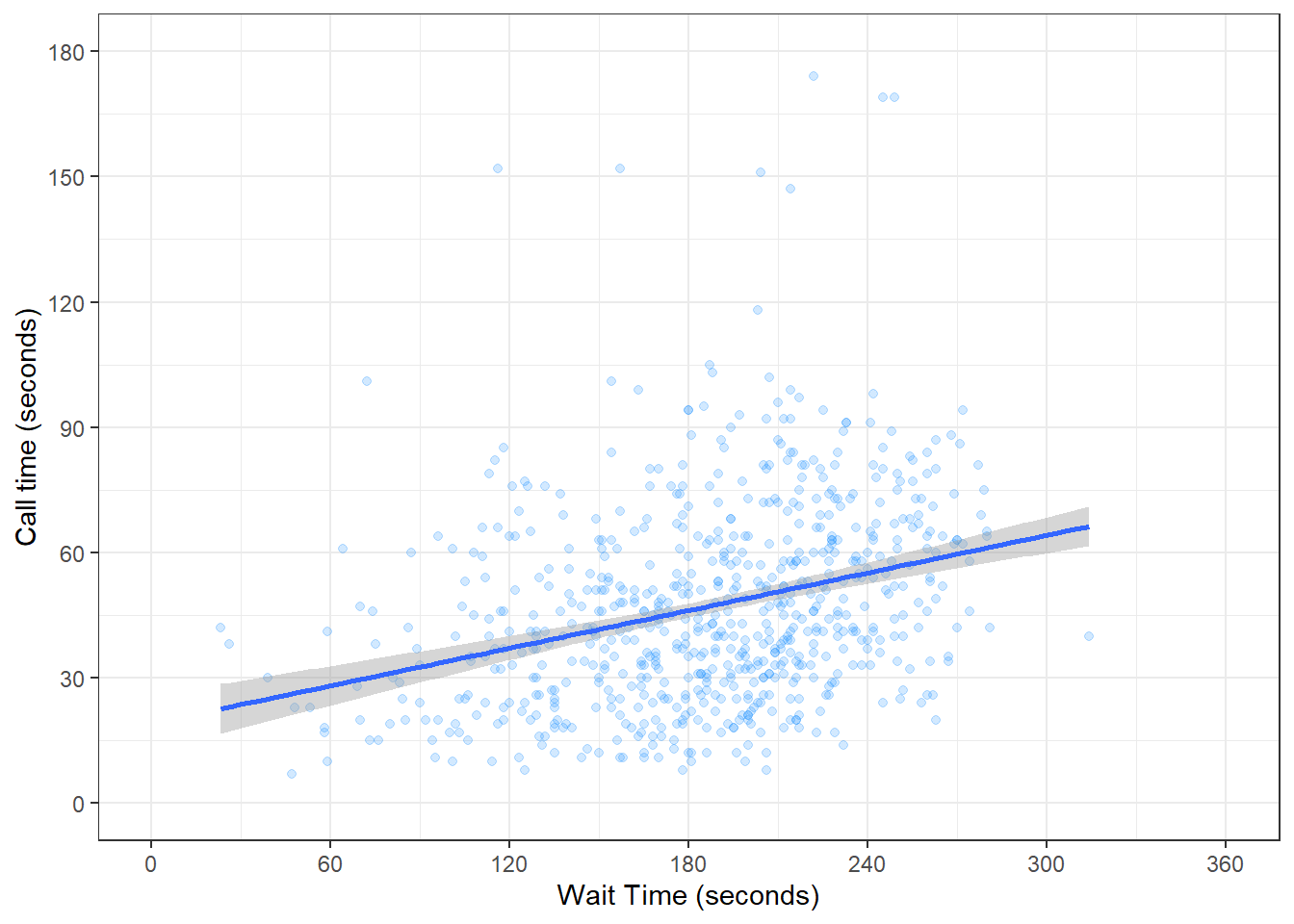
Figure 3.11: Changing the axis limits.
You can also set the limits argument inside the scale_ functions, but this actually removes any data that falls outside these limits, rather than cropping your plot, and this can change the appearance of certain types of plots like violin plots and density plots.
3.7.3 Themes
ggplot2 comes with several built-in themes, such as theme_minimal() and theme_bw(), but the ggthemes package provides even more themes to match different software, such as GoogleDocs or Stata, or publications, such as the Economist or the Wall Street Journal. Let's add the GoogleDocs theme, but change the font size to 18 with the base_size argument.
It's also worth highlighting that this code is starting to look quite complicated because of the number of layers, but because we've built it up slowly it should (hopefully!) make sense. If you see examples of ggplot2 code online that you'd like to adapt, build the plot up layer by layer and it will make it easier to understand what each layer adds.
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point(alpha = 0.2) +
geom_smooth(method = lm,
formula = y~x,
colour = rgb(0, .5, .8)) +
scale_x_continuous(name = "Wait Time (seconds)",
breaks = seq(from = 0, to = 600, by = 60)) +
scale_y_continuous(name = "Call time (seconds)",
breaks = seq(from = 0, to = 600, by = 30)) +
coord_cartesian(xlim = c(0, 360),
ylim = c(0, 180)) +
ggthemes::theme_gdocs(base_size = 18)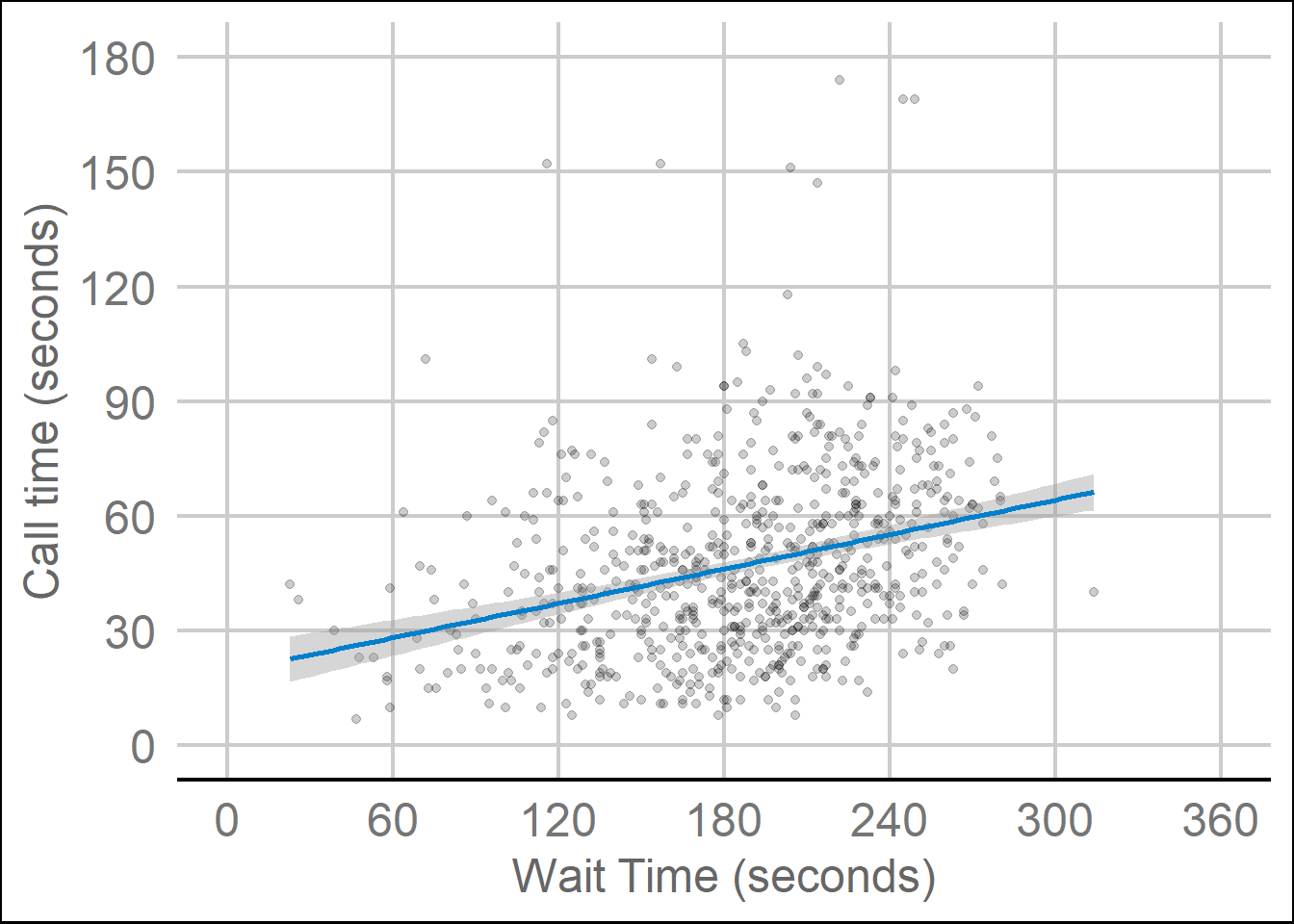
Figure 3.12: Changing the theme.
3.8 Appropriate plots
Now that you know how to build up a plot by layers and customise its appearance, you're ready to learn about some more plot types. Different types of data require different types of plots, so this section is organised by data type.
The ggplot2 cheat sheet is a great resource to help you find plots appropriate to your data, based on how many variables you're plotting and what type they are. The examples below all use the same customer satisfaction data, but each plot communicates something different.
We don't expect you to memorise all of the plot types or the methods for customising them, but it will be helpful to try out the code in the examples below for yourself, changing values to test your understanding.
3.8.1 Counting categories
3.8.1.1 Bar plot
If you want to count the number of things per category, you can use geom_bar(). You only need to provide a x mapping to geom_bar() because by default geom_bar() uses the number of observations in each group of x and the value for y, so you don't need to tell it what to put on the y-axis.
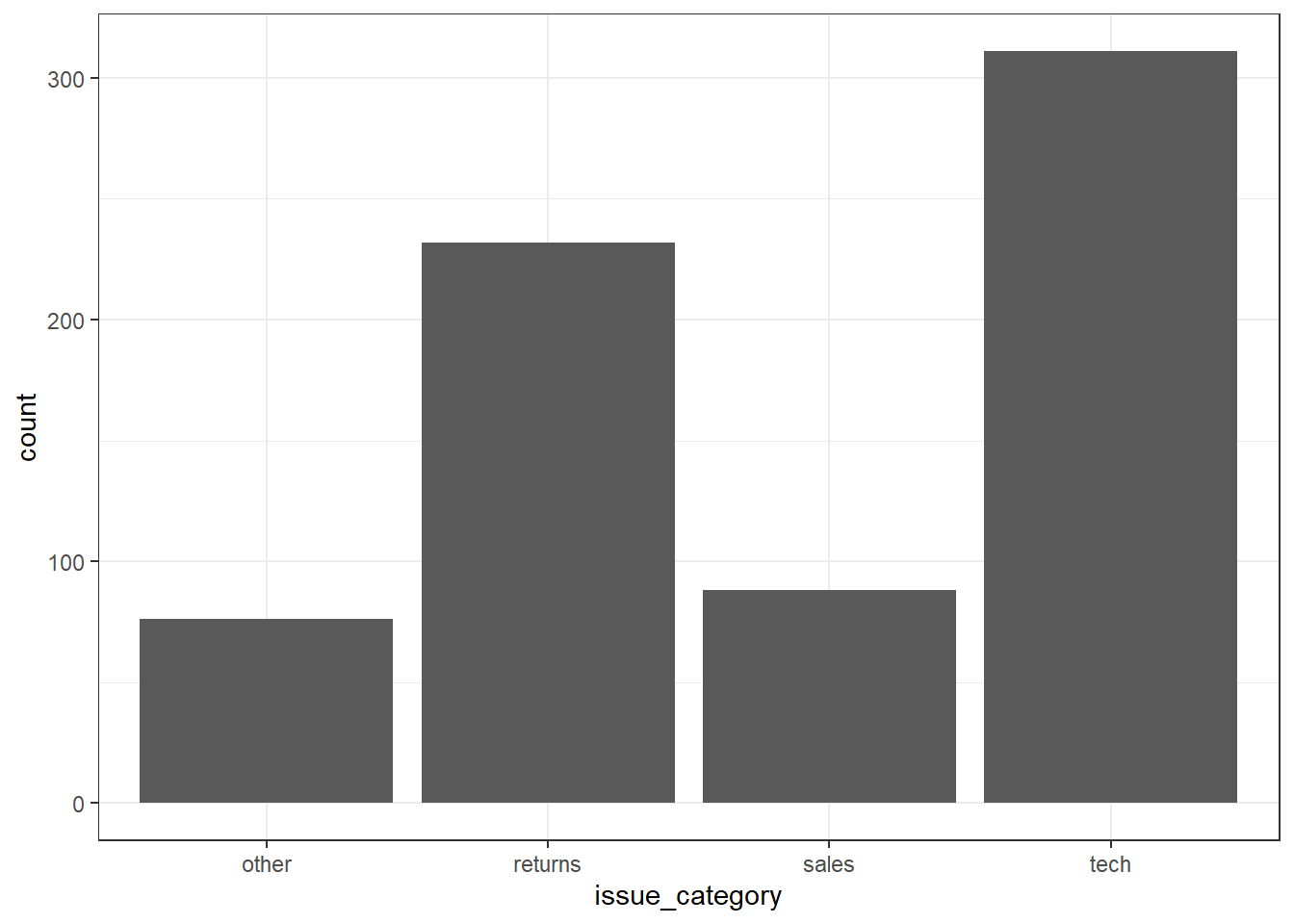
3.8.2 One continuous variable
If you have a continuous variable, like the number of seconds callers have to wait, you can use geom_histogram() or geom_density() to show the distribution. Just like geom_bar() you are only required to specify the x variable.
3.8.2.1 Histogram
A histogram splits the data into "bins" along the x-axis and shows the count of how many observations are in each bin along the y-axis.
ggplot(survey_data, aes(x = wait_time)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.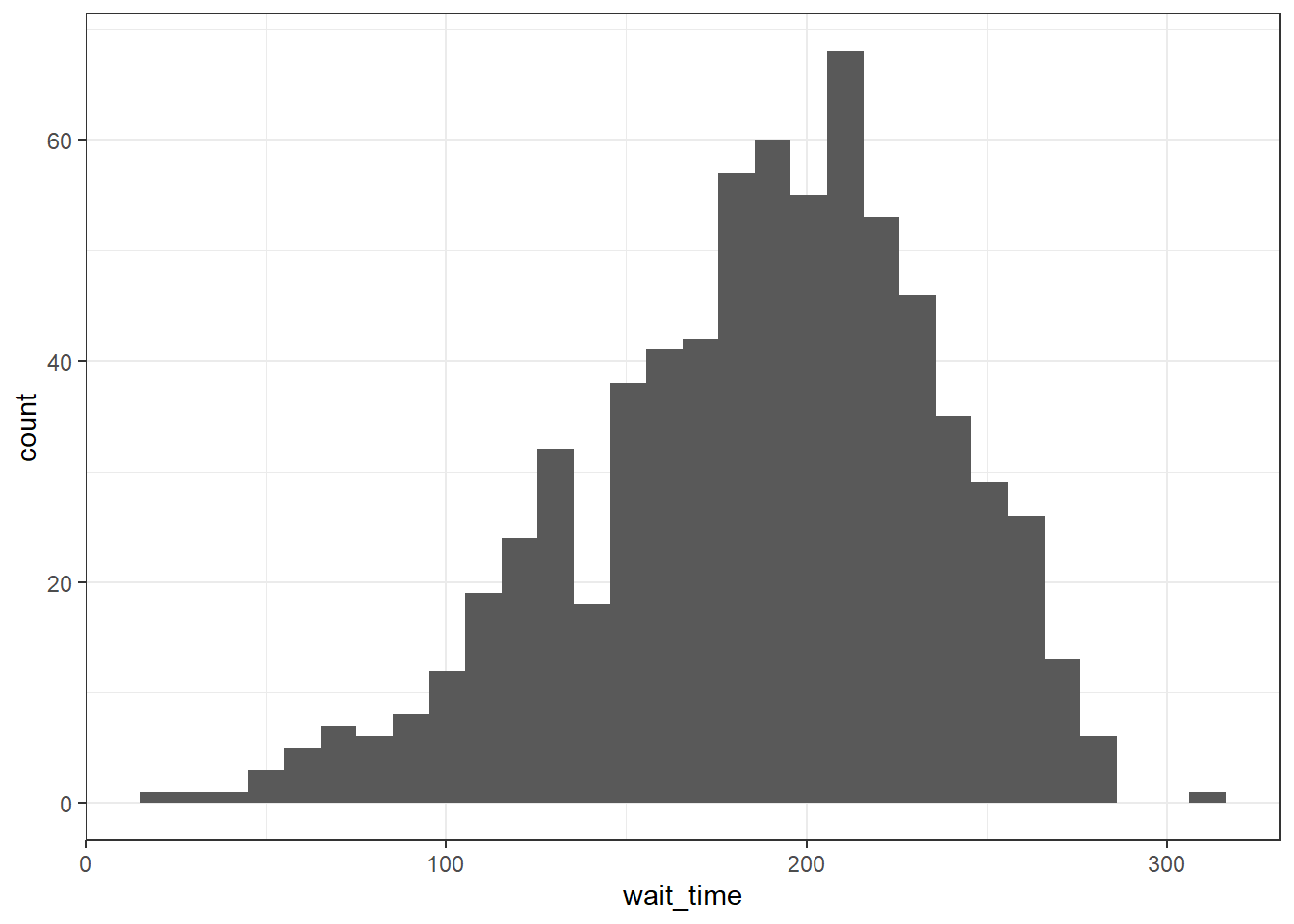
Figure 3.13: Histogram of wait times.
You should always set the binwidth or number of bins to something meaningful for your data (otherwise you get an annoying message). You might need to try a few options before you find something that looks good and conveys the meaning of your plot -- try changing the values of binwidth and bins below to see what works best.
# adjust width of each bar
ggplot(survey_data, aes(x = wait_time)) +
geom_histogram(binwidth = 15)
# adjust number of bars
ggplot(survey_data, aes(x = wait_time)) +
geom_histogram(bins = 5)By default, the bars start centered on 0, so if binwidth is set to 15, the first bar would include -7.5 to 7.5 seconds, which doesn't make much sense. We can set boundary = 0 so that each bar represents increments of 15 seconds starting from 0.
ggplot(survey_data, aes(x = wait_time)) +
geom_histogram(binwidth = 15, boundary = 0)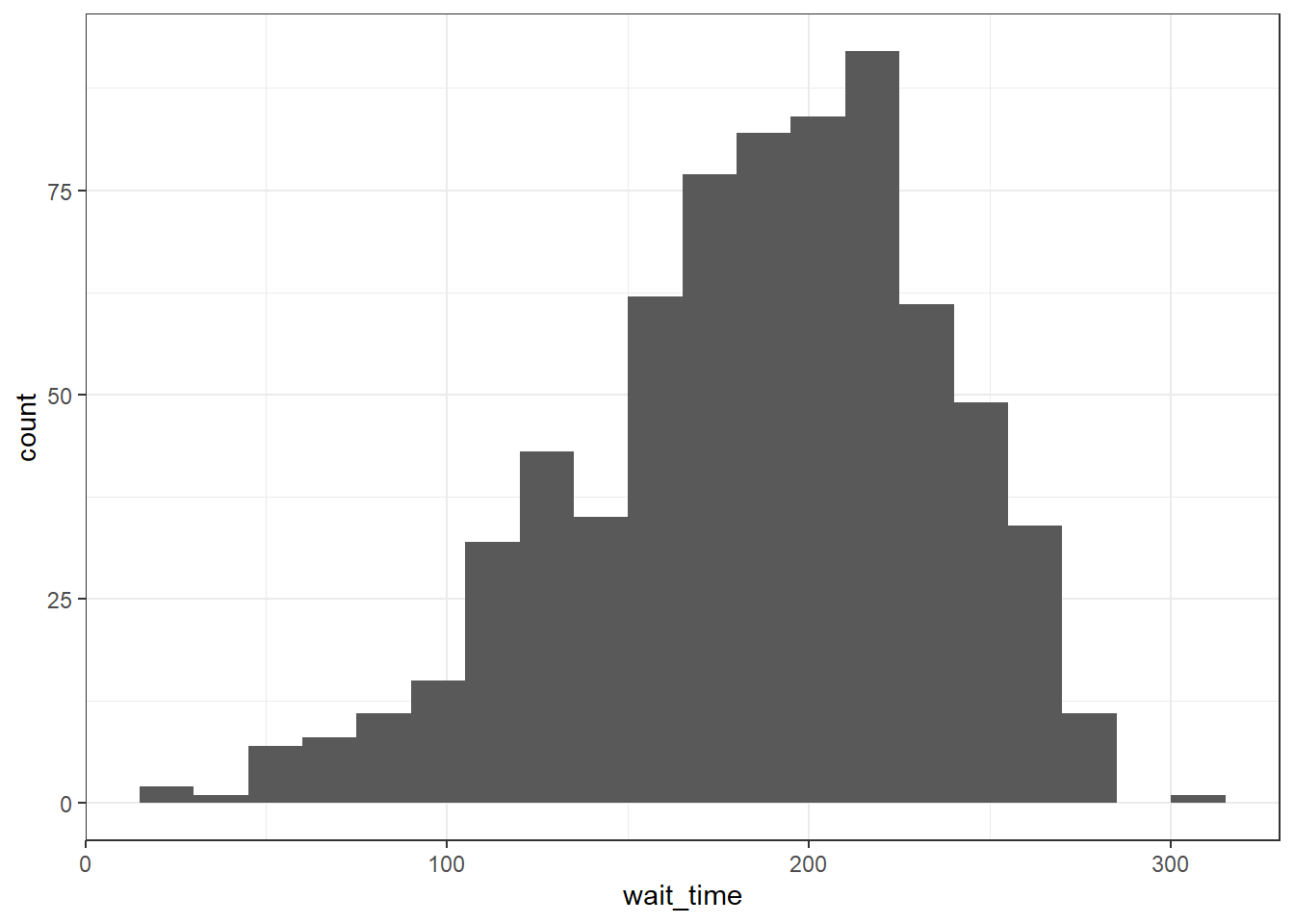
Finally, the default style of grey bars is ugly, so you can change that by setting the fill and colour, as well as using scale_x_continuous() to update the axis labels.
ggplot(survey_data, aes(x = wait_time)) +
geom_histogram(binwidth = 15,
boundary = 0,
fill = "white",
color = "black") +
scale_x_continuous(name = "Wait time (seconds)",
breaks = seq(0, 600, 60))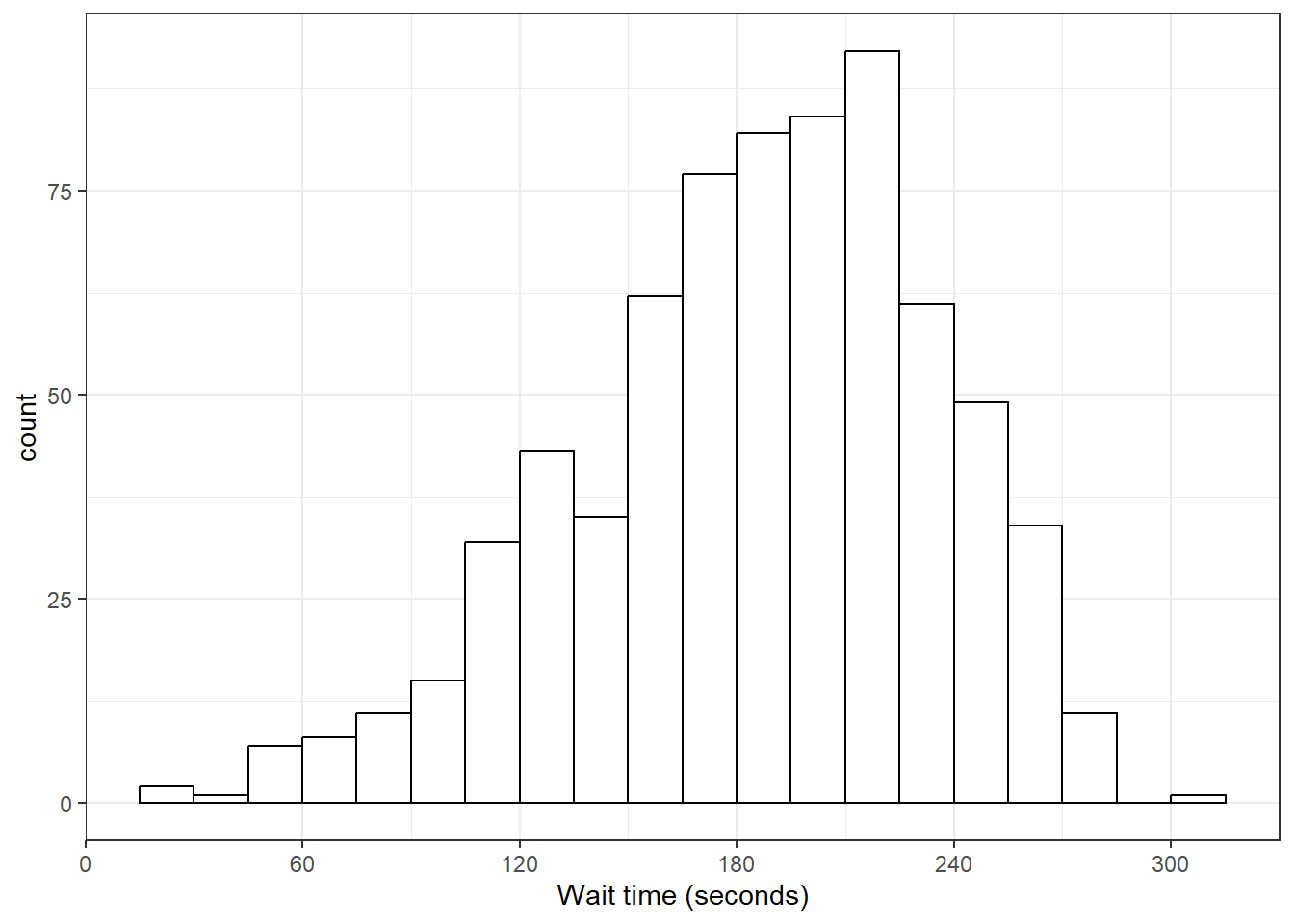
Figure 3.14: Histogram with custom styles.
3.8.2.2 Frequency plot
Rather than plotting each bin as a bar, you can connect a line across the top of each bin using a frequency plot. The function geom_freqpoly() works the same as geom_histogram(), except it can't take a fill argument because it's just a line.
ggplot(survey_data, aes(x = wait_time)) +
scale_x_continuous(name = "Wait time (seconds)",
breaks = seq(0, 600, 60)) +
geom_freqpoly(boundary = 0, binwidth = 15,
color = "black")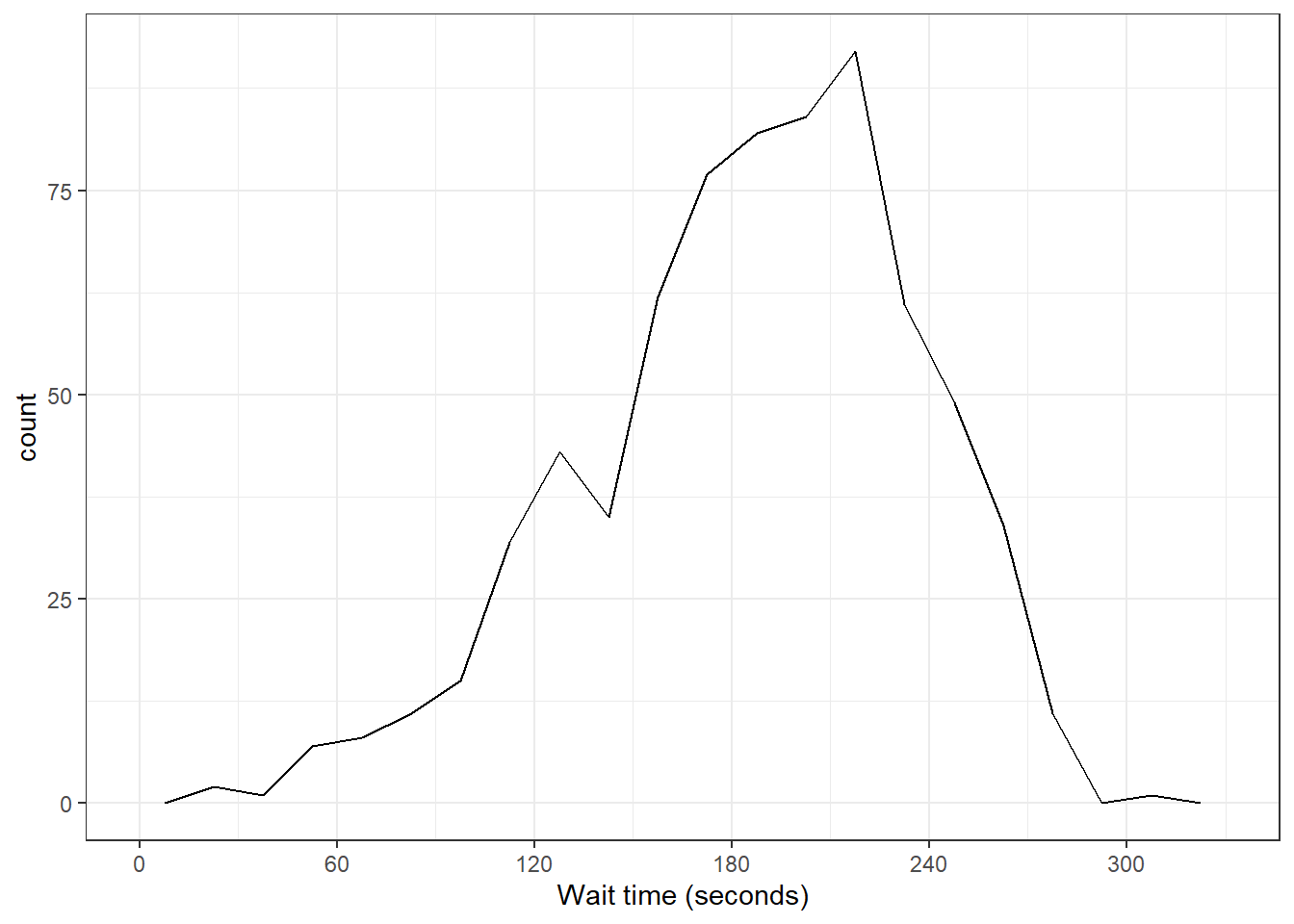
3.8.2.3 Density plot
If the distribution is smooth, a density plot is often a better way to show the distribution. A density plot doesn't need the binwidth or boundary arguments because it doesn't split the data into bins, but it can have fill.
ggplot(survey_data, aes(x = wait_time)) +
scale_x_continuous(name = "Wait time (seconds)",
breaks = seq(0, 600, 60)) +
geom_density(fill = "purple", color = "black")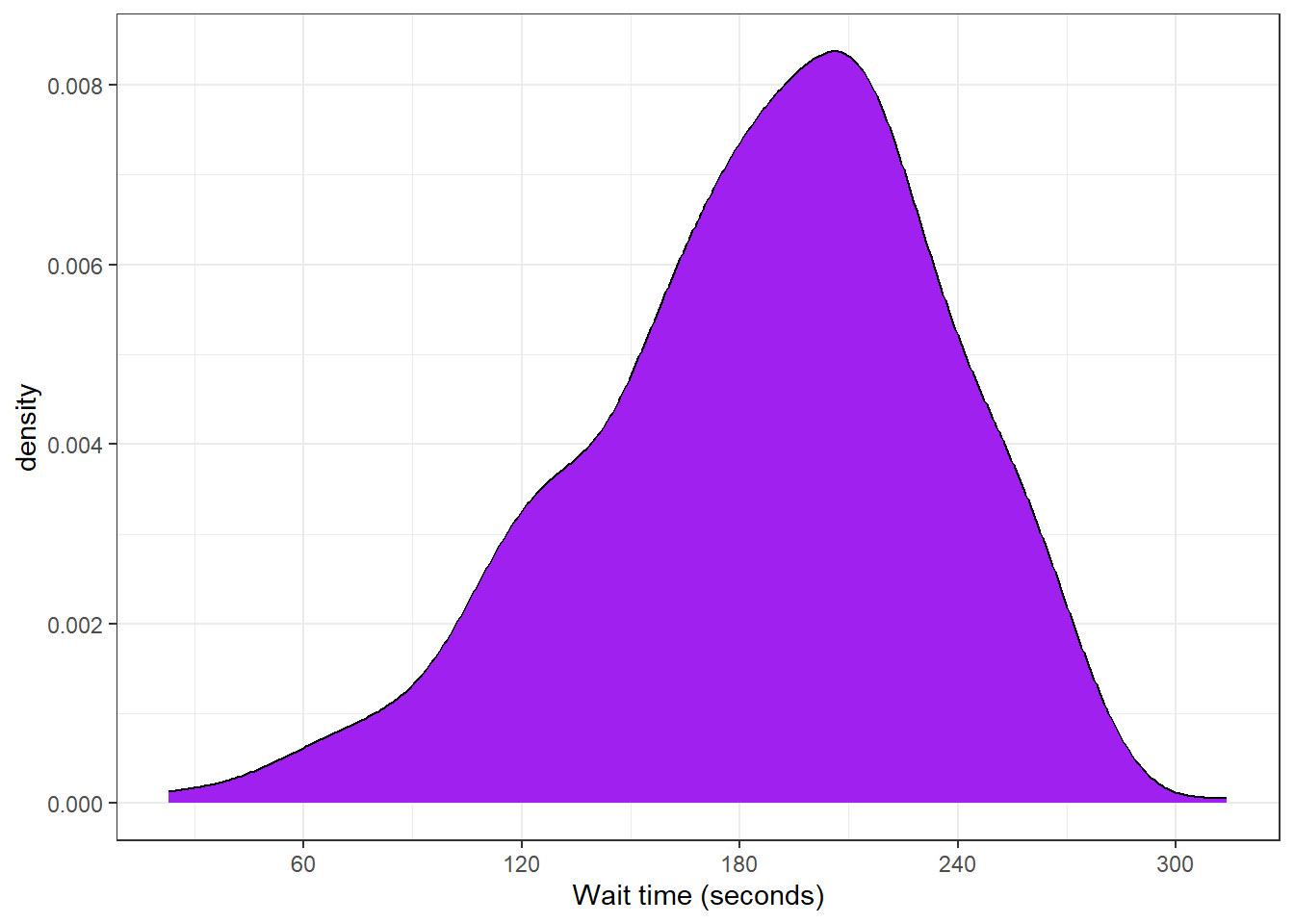
3.8.3 Grouped continuous variables
There are several ways to compare continuous data across groups. Which you choose depends on what point you are trying to make with the plot.
3.8.3.1 Subdividing distributions
In previous plots, we have used fill purely for visual reasons, e.g., we have changed the colour of the histogram bars to make them look nicer. However, you can also use fill to represent another variable so that the colours become meaningful.
Setting the fill aesthetic in the mapping will produce different coloured bars for each category of the fill variable, in this case issue_category. By default, the categories are positioned stacked on top of each other - this is potentially not a great way of visualising this, we'll come back to a better way to do this with facet plots in the next section.
ggplot(survey_data, aes(x = wait_time, fill = issue_category)) +
geom_histogram(boundary = 0,
binwidth = 15,
color = "black")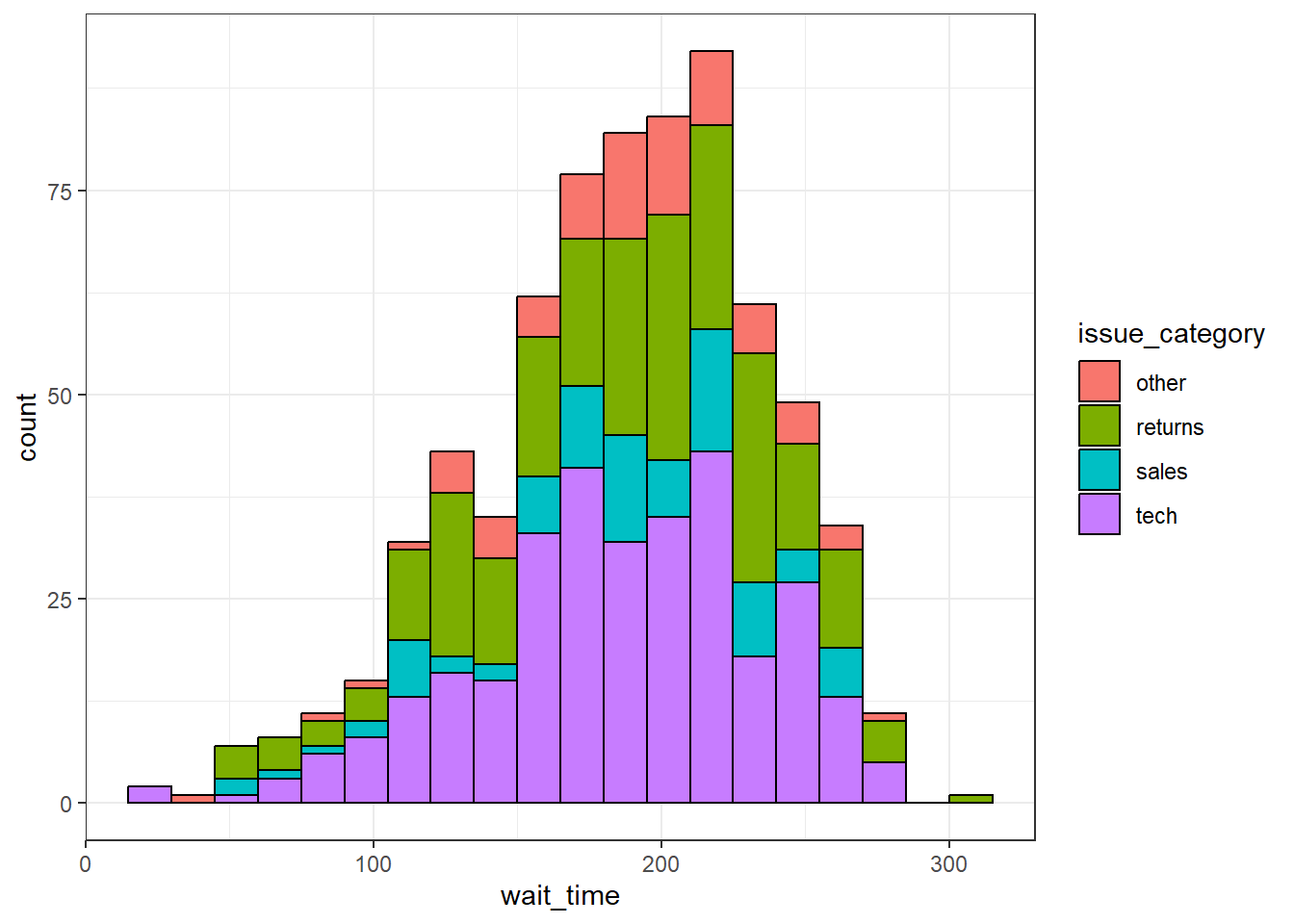
Figure 3.15: Histogram with categories represented by fill.
You can also use a grouped density plot. It's often better to adjust the transparency of the plot so that you can better see the different distributions. How useful these plots are does depend on your data.
ggplot(survey_data, aes(x = wait_time, fill = issue_category)) +
geom_density(alpha = .4)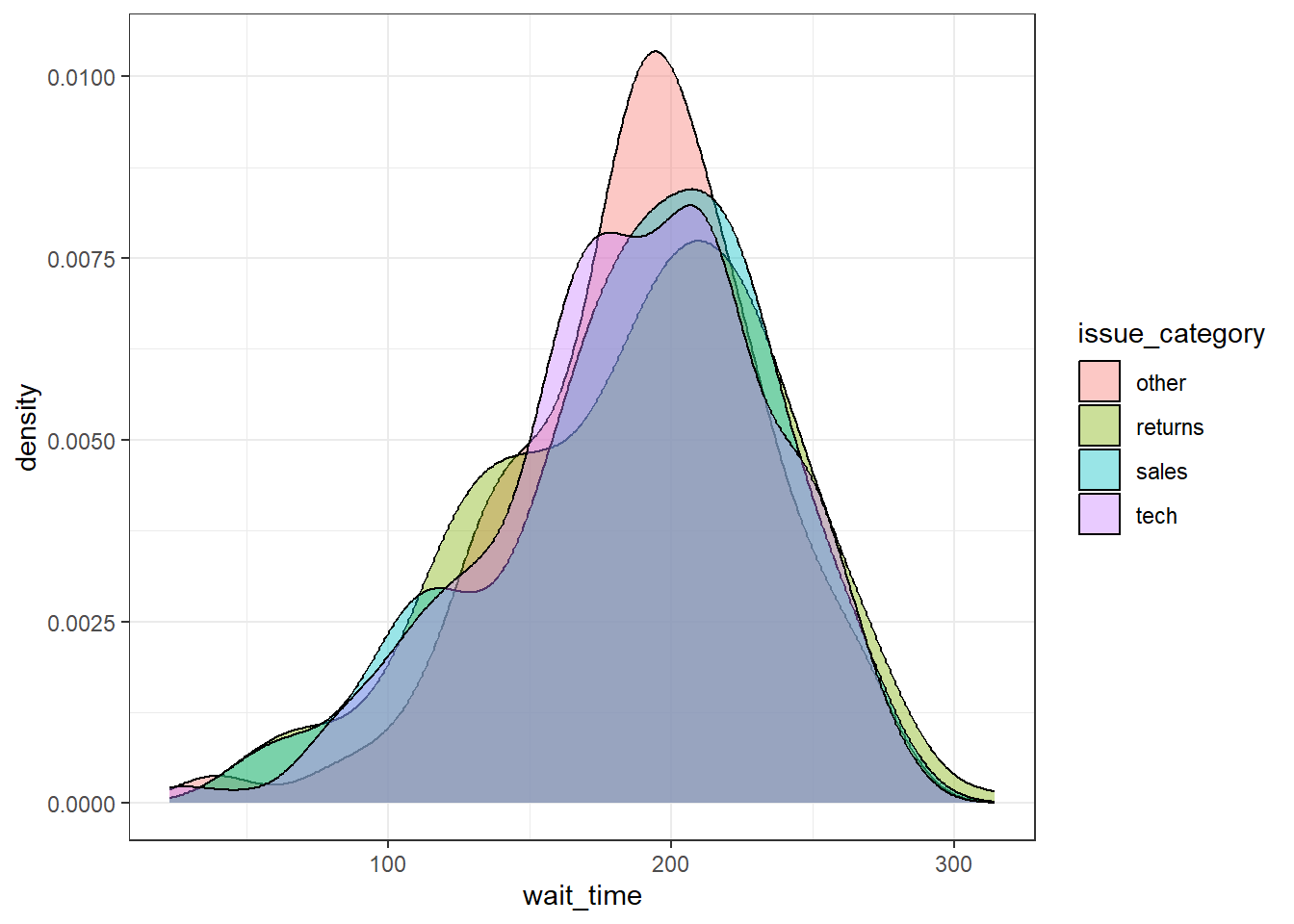
Figure 3.16: Grouped density plot
3.8.3.2 Violin plot
Another way to compare groups of continuous variables is the violin plot. This is like a density plot, but rotated 90 degrees and mirrored - the fatter the violin, the larger proportion of data points there are at that value.
ggplot(survey_data, aes(x = issue_category, y = wait_time)) +
geom_violin()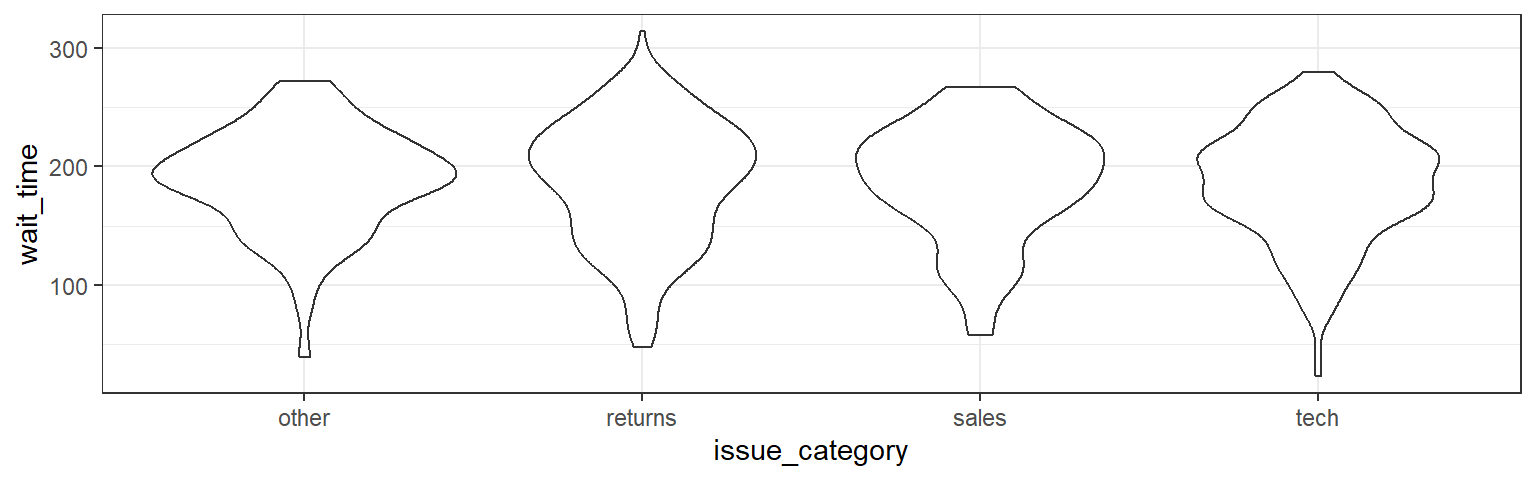
Figure 3.17: Violin-plot.
3.8.3.3 Boxplot
Boxplots serve a similar purpose to violin plots. They don't show you the shape of the distribution, but rather some statistics about it. The middle line represents the median; half the data are above this line and half below it. The box encloses the 25th to 75th percentiles of the data, so 50% of the data falls inside the box. The "whiskers" extending above and below the box extend 1.5 times the height of the box, although you can change this with the coef argument. The points show outliers -- individual data points that fall outside of this range.
ggplot(survey_data, aes(x = issue_category, y = wait_time)) +
geom_boxplot()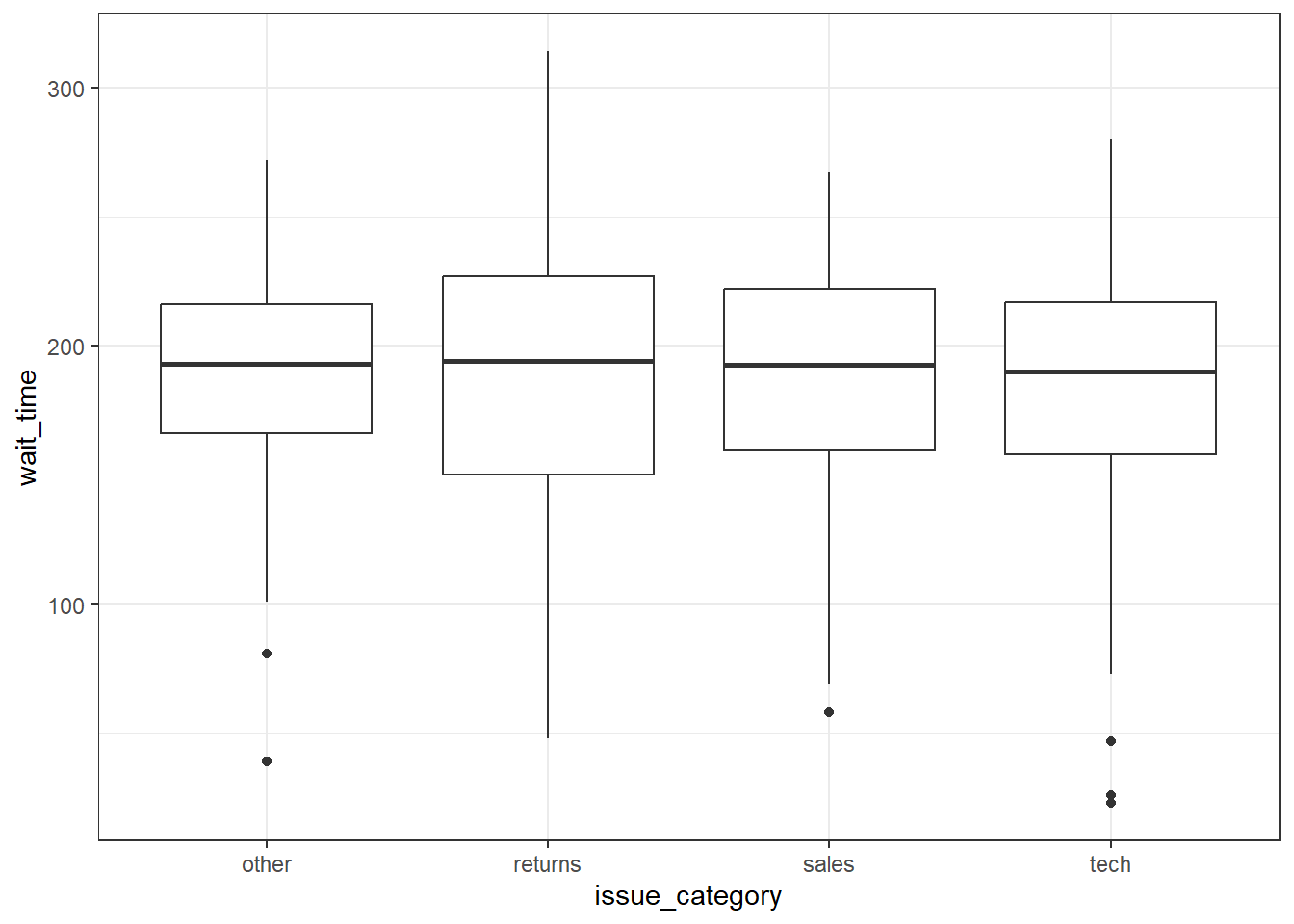
Figure 3.18: Basic boxplot.
3.8.3.4 Combo plots
Violin plots are frequently layered with other geoms that represent the mean or median values in the data. This is a lot of code, to help your understanding a) run it layer by layer to see how it builds up and b) change the values throughout the code
# add fill and colour to the mapping
ggplot(survey_data, aes(x = issue_category,
y = wait_time,
fill = issue_category,
colour = issue_category)) +
scale_x_discrete(name = "Issue Category") +
scale_y_continuous(name = "Wait Time (seconds)",
breaks = seq(0, 600, 60)) +
coord_cartesian(ylim = c(0, 360)) +
guides(fill = "none", colour = "none") +
# add a line at median (50%) score
geom_violin(alpha = 0.4,
draw_quantiles = 0.5) +
# add a boxplot
geom_boxplot(width = 0.25,
fill = "white",
alpha = 0.75) +
# add a point that represents the mean
stat_summary(fun = mean,
geom = "point",
size = 2) +
ggtitle("ViolinBox")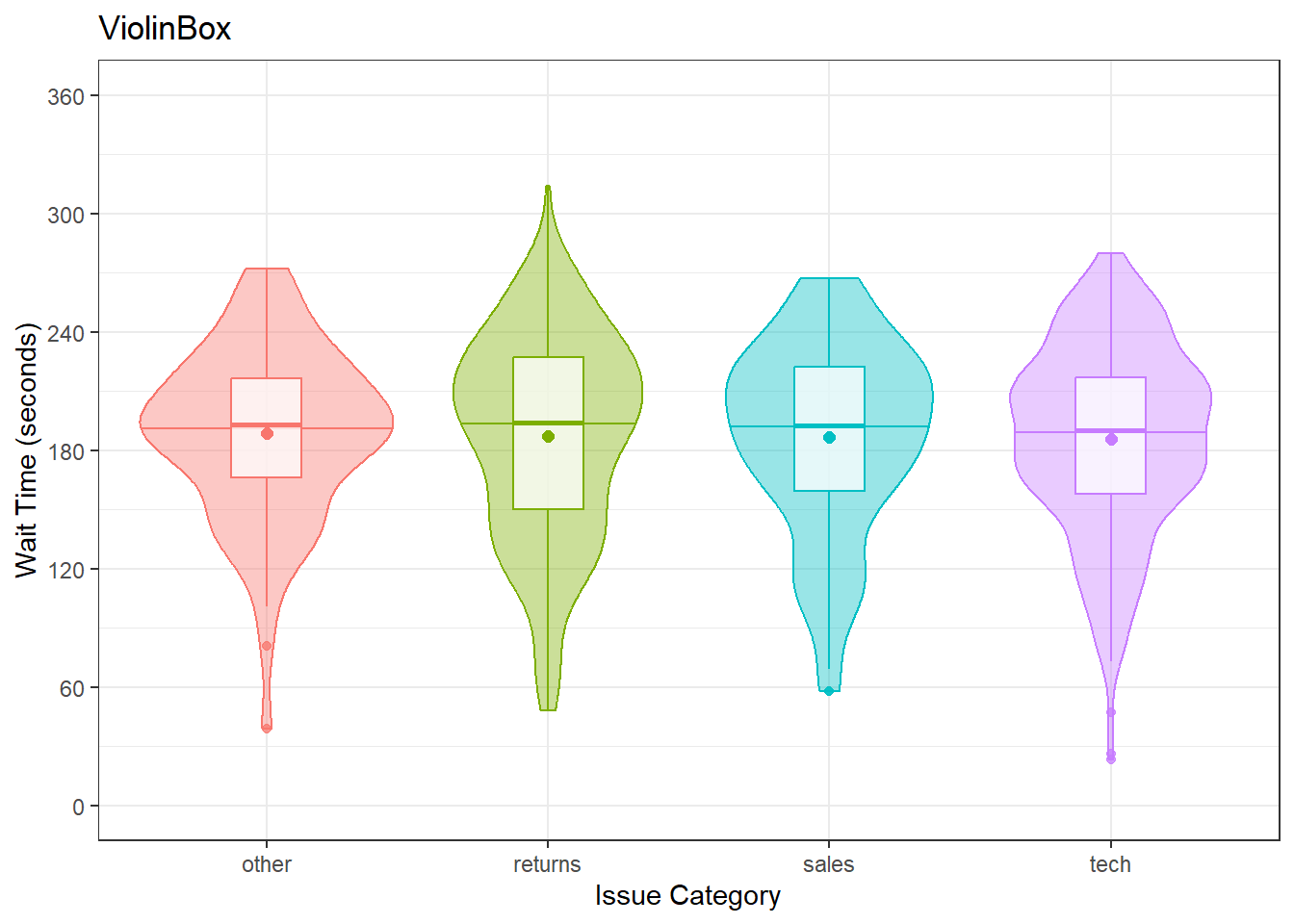
Figure 3.19: Violin plots combined with different methods to represent means and medians.
3.8.4 Two continuous variables
When you want to see how two continuous variables are related, set one as the x-axis and the other as the y-axis. Usually, if one variable causes the other, you plot the cause on the x-axis and the effect on the y-axis. Here, we want to see if longer wait times cause the calls to be longer.
3.8.4.1 Scatterplot
The function to create a scatterplot is called geom_point().
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point()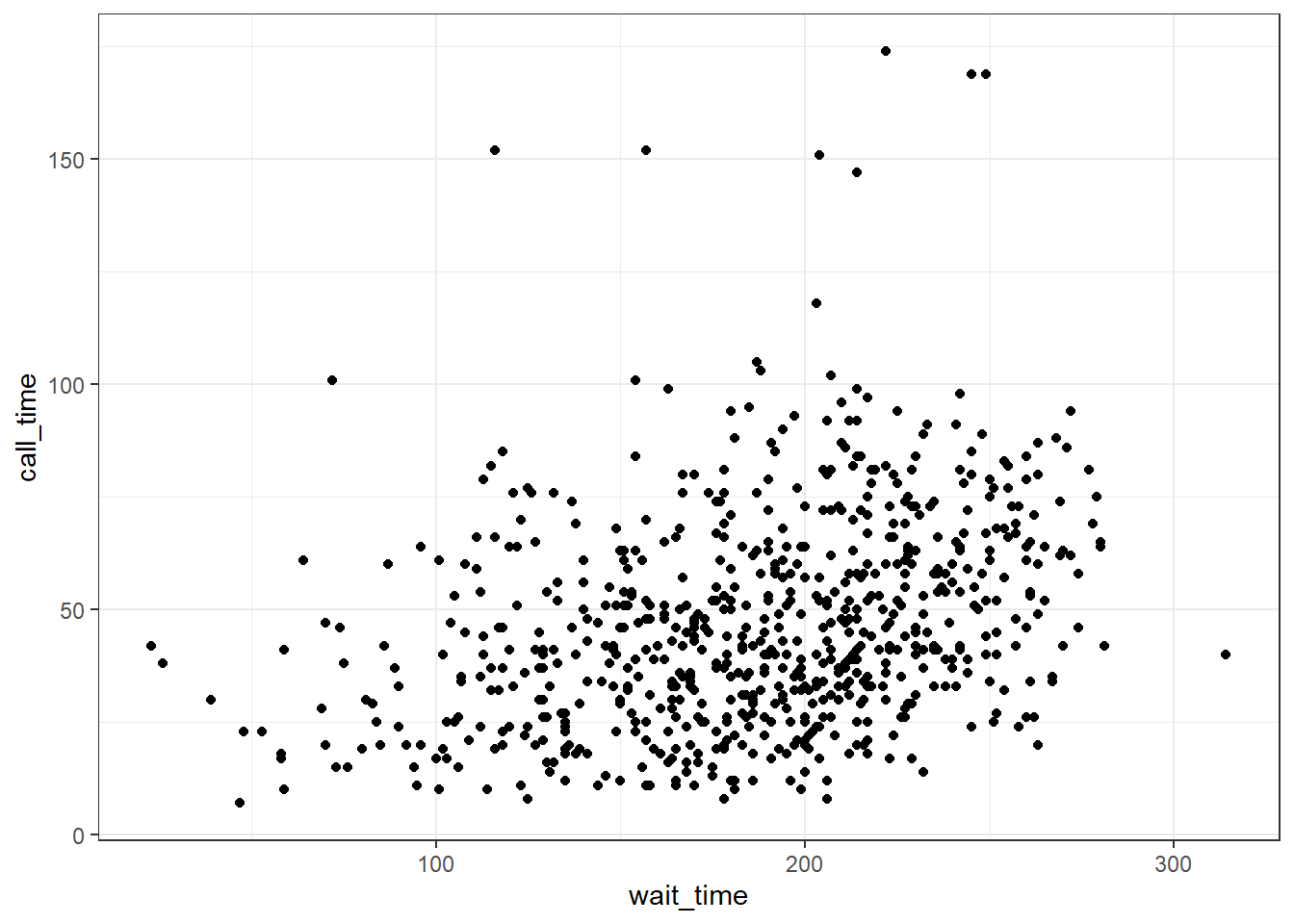
Figure 3.20: Scatterplot with geom_point().
3.8.4.2 Trendlines
In Figure 3.3, we emphasised the relationship between wait time and call time with a trendline created by geom_smooth() using the argument method = lm ("lm" stands for "linear model" or a straight line relationship). You can also set method = loess to visualise a non-linear relationship.
lm_plot <-
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point(alpha = 0.2) +
geom_smooth(method = lm) +
ggtitle("method = lm")
loess_plot <-
ggplot(survey_data, aes(x = wait_time, y = call_time)) +
geom_point(alpha = 0.2) +
geom_smooth(method = loess) +
ggtitle("method = loess")
lm_plot + loess_plot## `geom_smooth()` using formula = 'y ~ x'
## `geom_smooth()` using formula = 'y ~ x'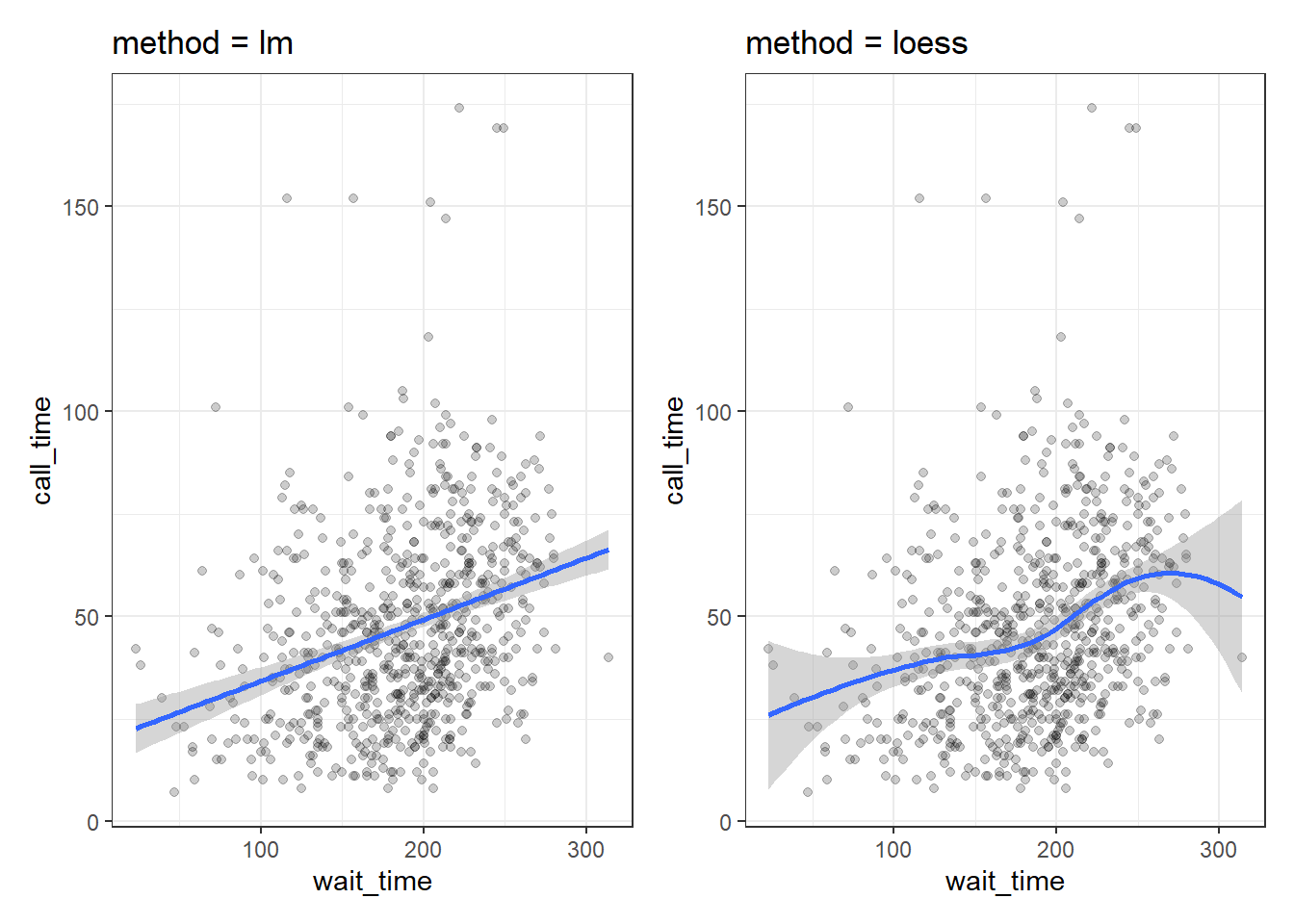
Figure 3.21: Different ways to show the relationship between two continuous variables.
If there isn't much data at the extremes of the x-axis, the curve can be very uncertain. This is represented by the wider shaded area, which means that the true relationship might be anywhere within that area. Add the argument se = FALSE to geom_smooth() to remove this "standard error" shading.
3.8.5 Overplotting
When you have a limited range of numeric values, such as an ordinal rating scale, sometimes overlapping data makes it difficult to see what is going on in a point plot. For example, the plot below shows satisfaction ratings by call time but because all the ratings are 1, 2, 3, 4 or 5, it makes it hard to see exactly how many data points there are at each point.
In this section, we'll explore a few options for dealing with this.
ggplot(survey_data, aes(x = call_time, y = satisfaction)) +
geom_point()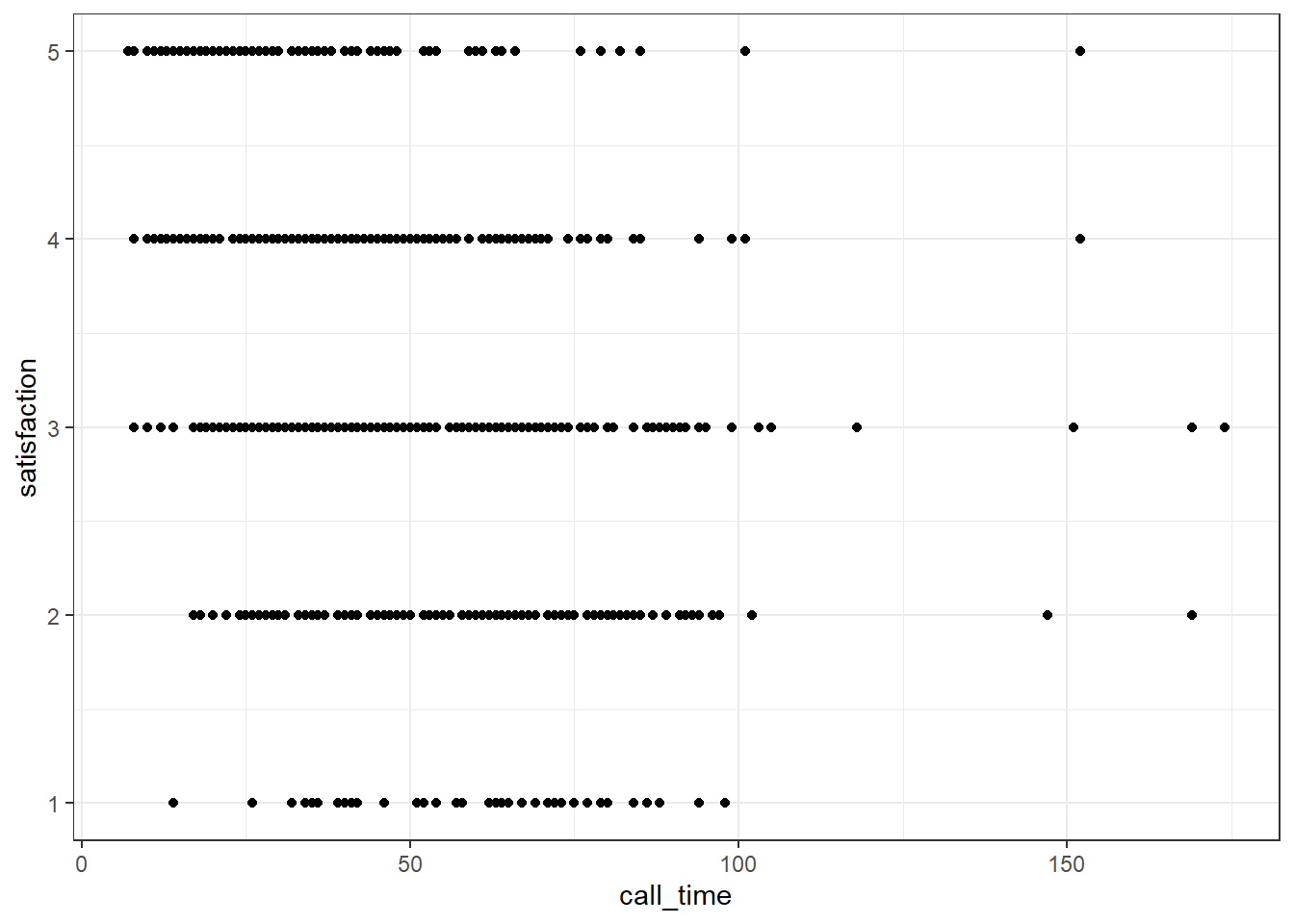
Figure 3.22: Overlapping data.
3.8.5.1 Jitter plot
You can use geom_jitter() to move the points around a bit to make them easier to see. You can also set alpha transparency. Here, the x-axis is continuous, so there is no need to jitter the width, but the y-axis is ordinal categories, so the height is jittered between -0.2 and +0.2 away from the true y-value. It can help to play around with these values to understand what the jitter is doing.
ggplot(survey_data, aes(x = call_time, y = satisfaction)) +
geom_jitter(width = 0, height = .2, alpha = 0.5)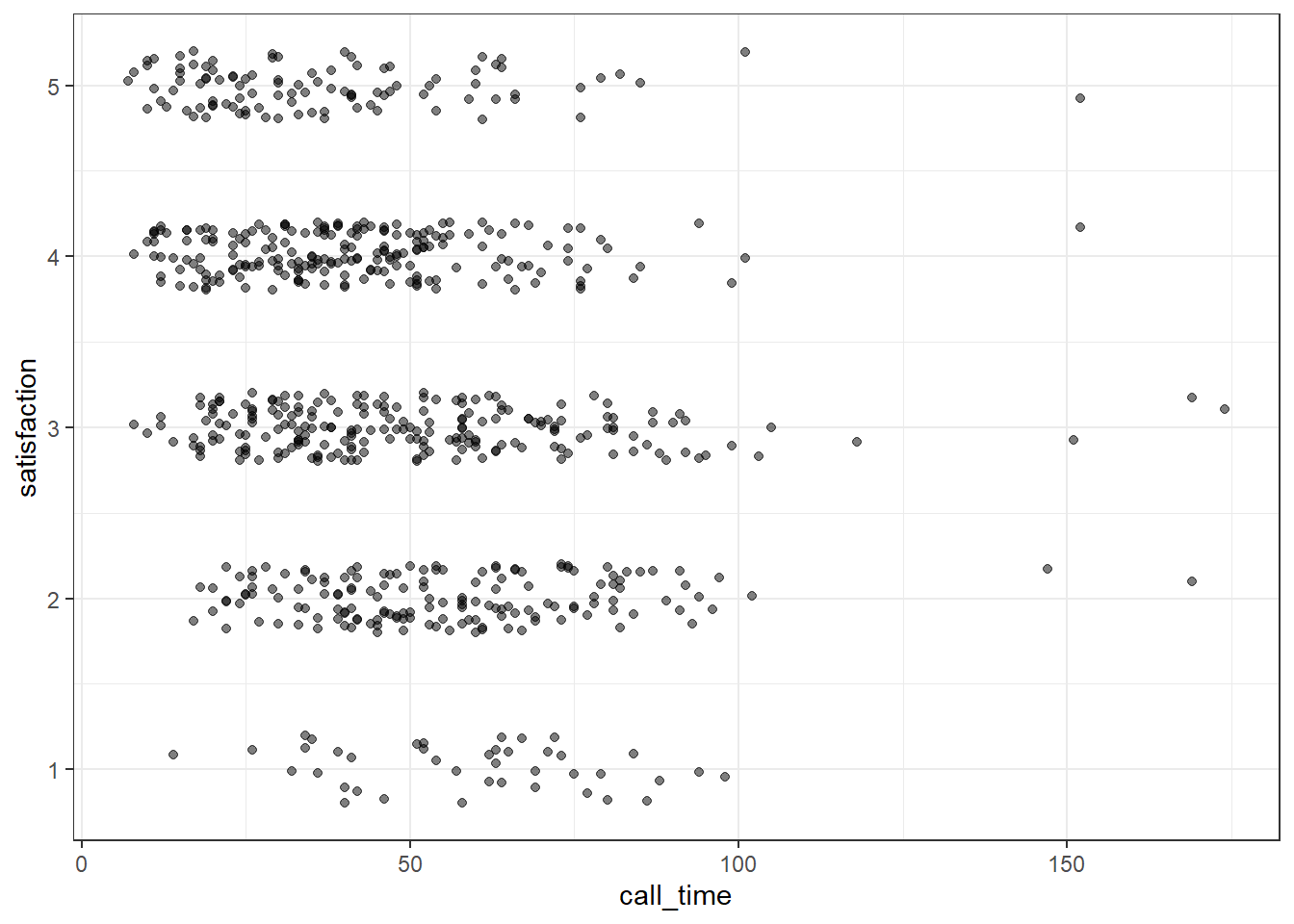
Figure 3.23: Jitter plot.
3.8.5.2 Facets
Alternatively, you can use facet_wrap() to create a separate plot for each level of satisfaction. facet_wrap() uses the tilde (~) symbol, which you can roughly translate as "by", e.g., facet the plot by satisfaction rating. The labeller function controls the labels above each plot. label_both specifies that we want both the variable name (satisfaction) and the value (e.g., 1) printed on the plot to make it easier to read.
ggplot(survey_data, aes(x = call_time)) +
geom_histogram(binwidth = 10,
boundary = 0,
fill = "dodgerblue",
color = "black") +
facet_wrap(~satisfaction,
ncol = 1, # try changing this to 2
labeller = label_both) +
scale_x_continuous(name = "Call Time (seconds)",
breaks = seq(0, 600, 30))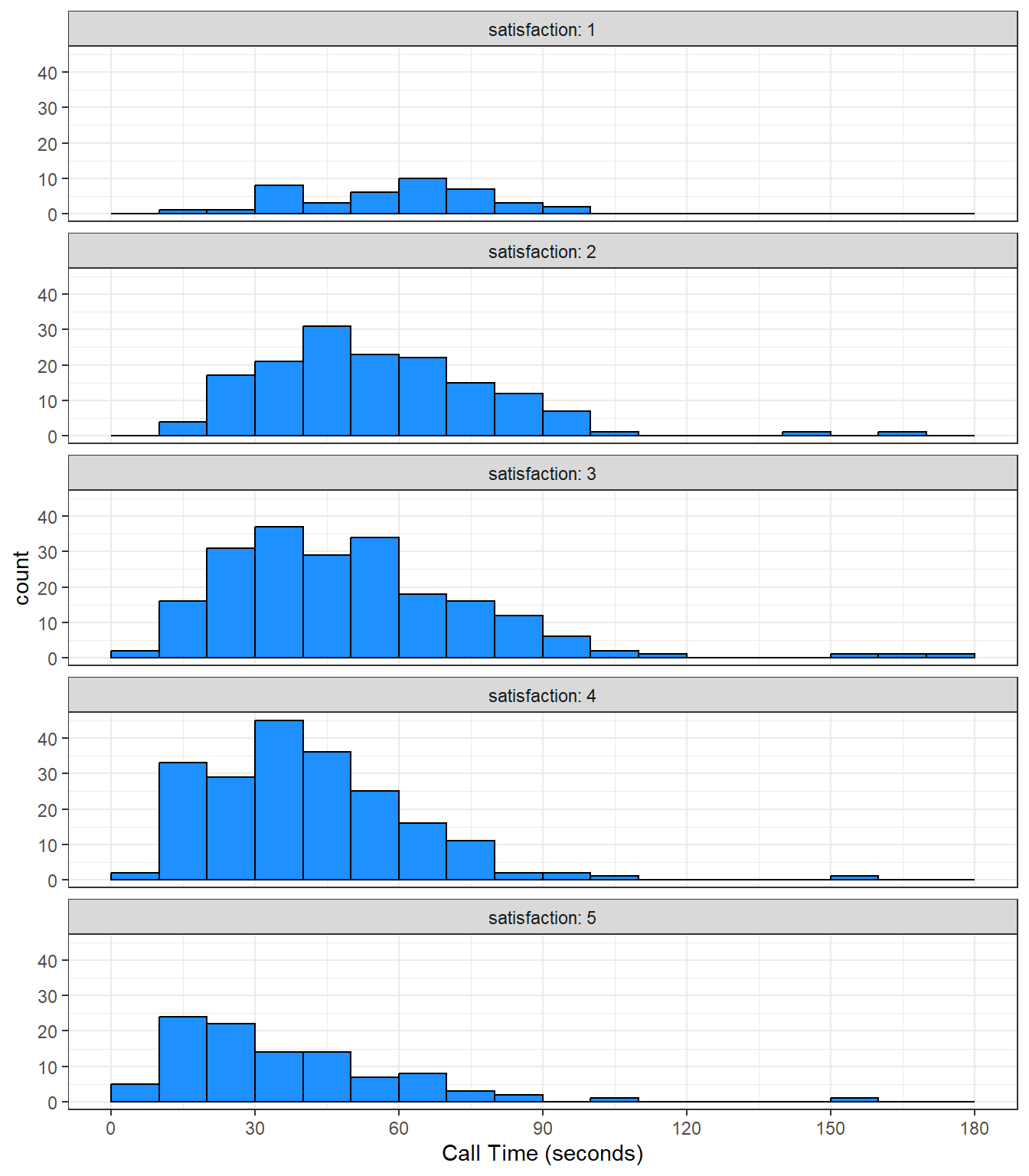
Figure 3.24: A histogram with facets.
Facets can also be a good alternative to some of the grouped plots we did earlier. For example, instead of creating a grouped density plot, you could facet it. We don't need to make the plots transparent for readablity so we remove alpha, although we still want a different colour for each plot so we keep fill = issue_category but remove the unnecessary legend.
ggplot(survey_data, aes(x = wait_time, fill = issue_category)) +
geom_density() +
facet_wrap(~ issue_category) +
guides(fill = "none")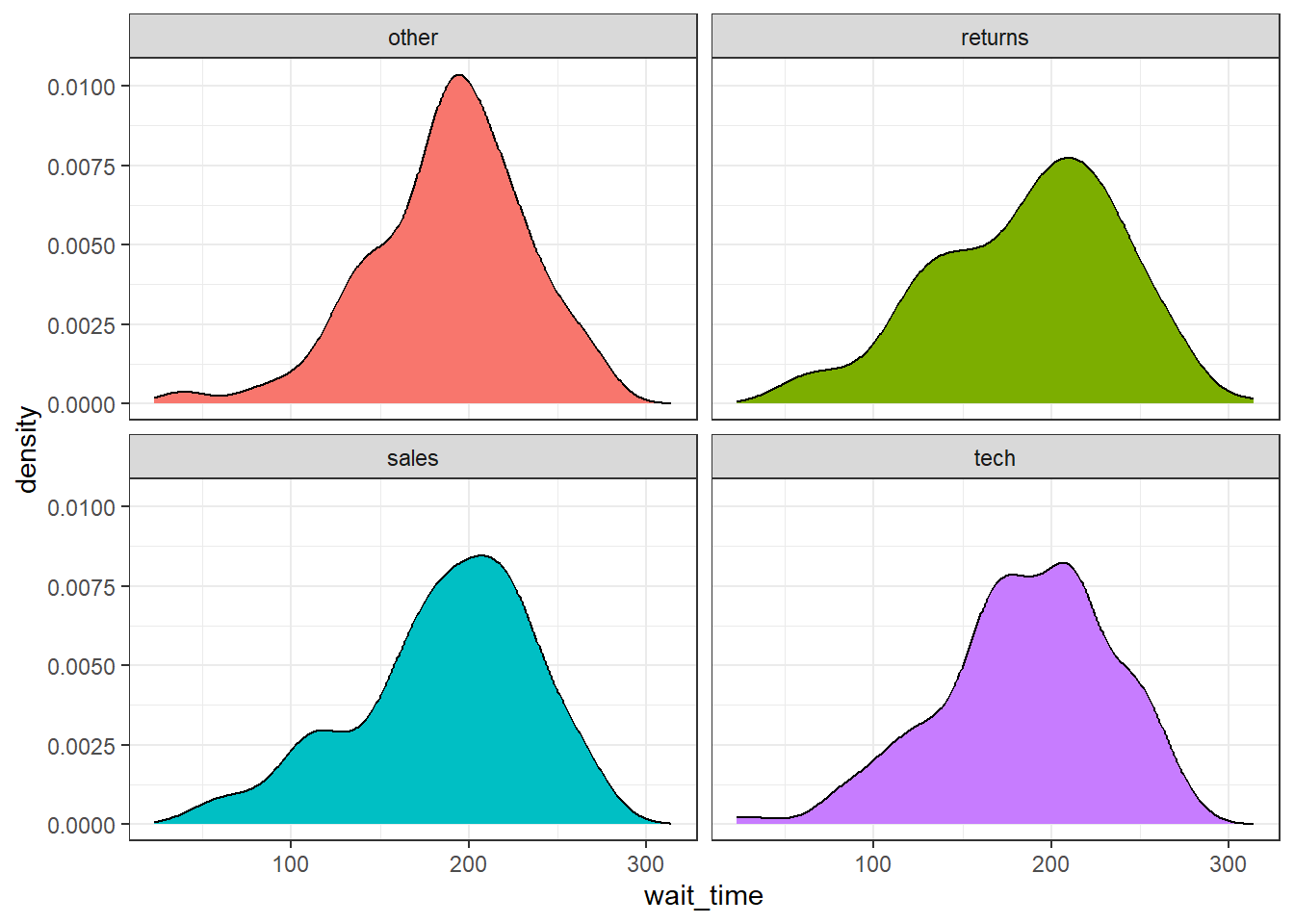
Figure 3.25: Faceted density plot
These are not, by any means, all the plot types that you can make in R. This chapter just gave you a basic overview. The further resources section at the end of this chapter lists many resources, but the R Graph Gallery is an especially useful one to get inspiration for the kinds of beautiful plots you can make in R.
3.9 Exercises
To consolidate what you've learned in this session, use the built-in starwars data set to create each of the following:
- A histogram of heights
- A scatterplot of height v mass with line of best fit
- A bar chart of counts for gender
# load data
data("starwars")
# histogram
ggplot(starwars, aes(x = height)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 6 rows containing non-finite values (`stat_bin()`).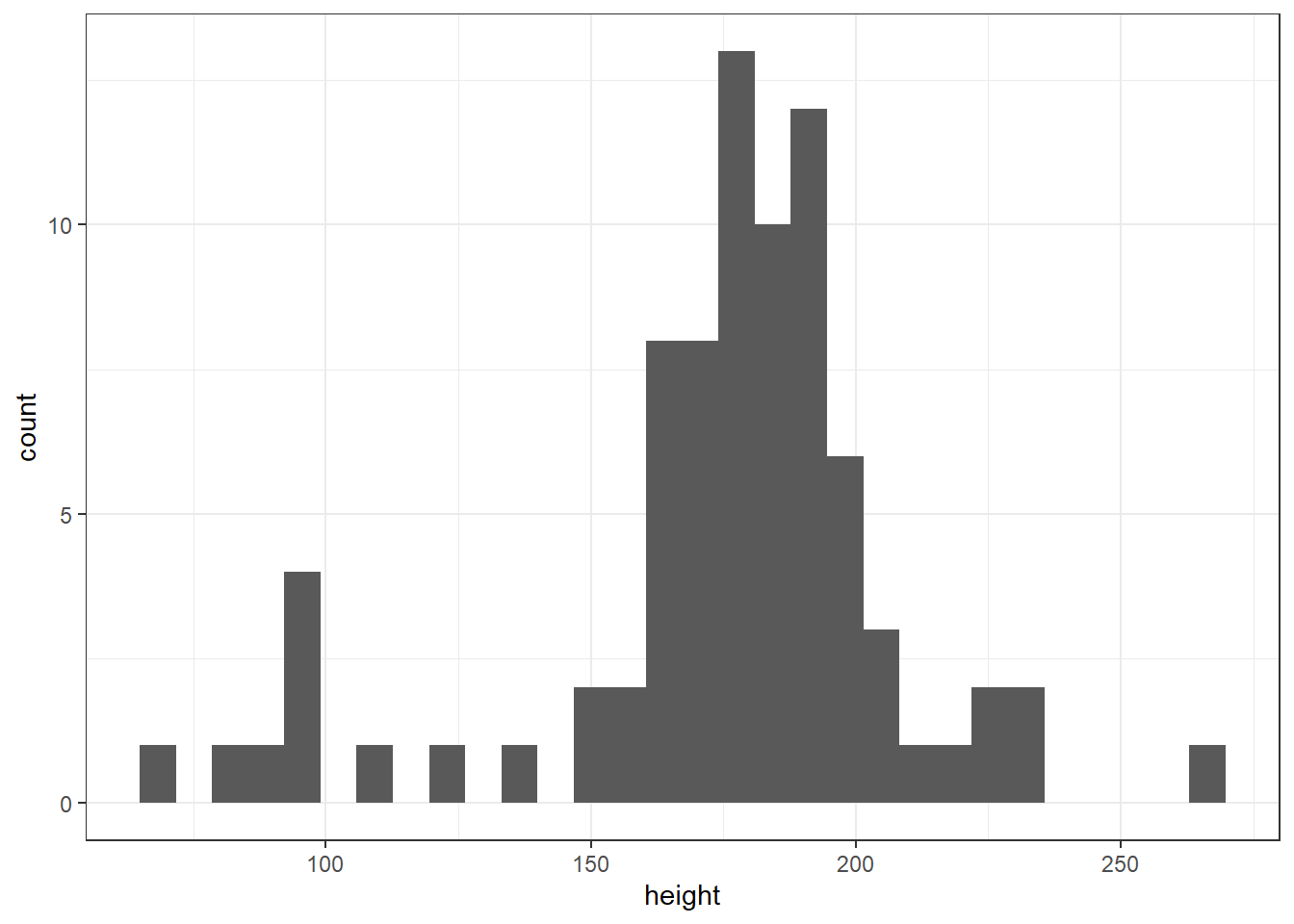
# scatterplot
ggplot(starwars, aes(x = height, y = mass)) +
geom_point() +
geom_smooth()## `geom_smooth()` using method = 'loess' and formula = 'y ~ x'## Warning: Removed 28 rows containing non-finite values (`stat_smooth()`).## Warning: Removed 28 rows containing missing values (`geom_point()`).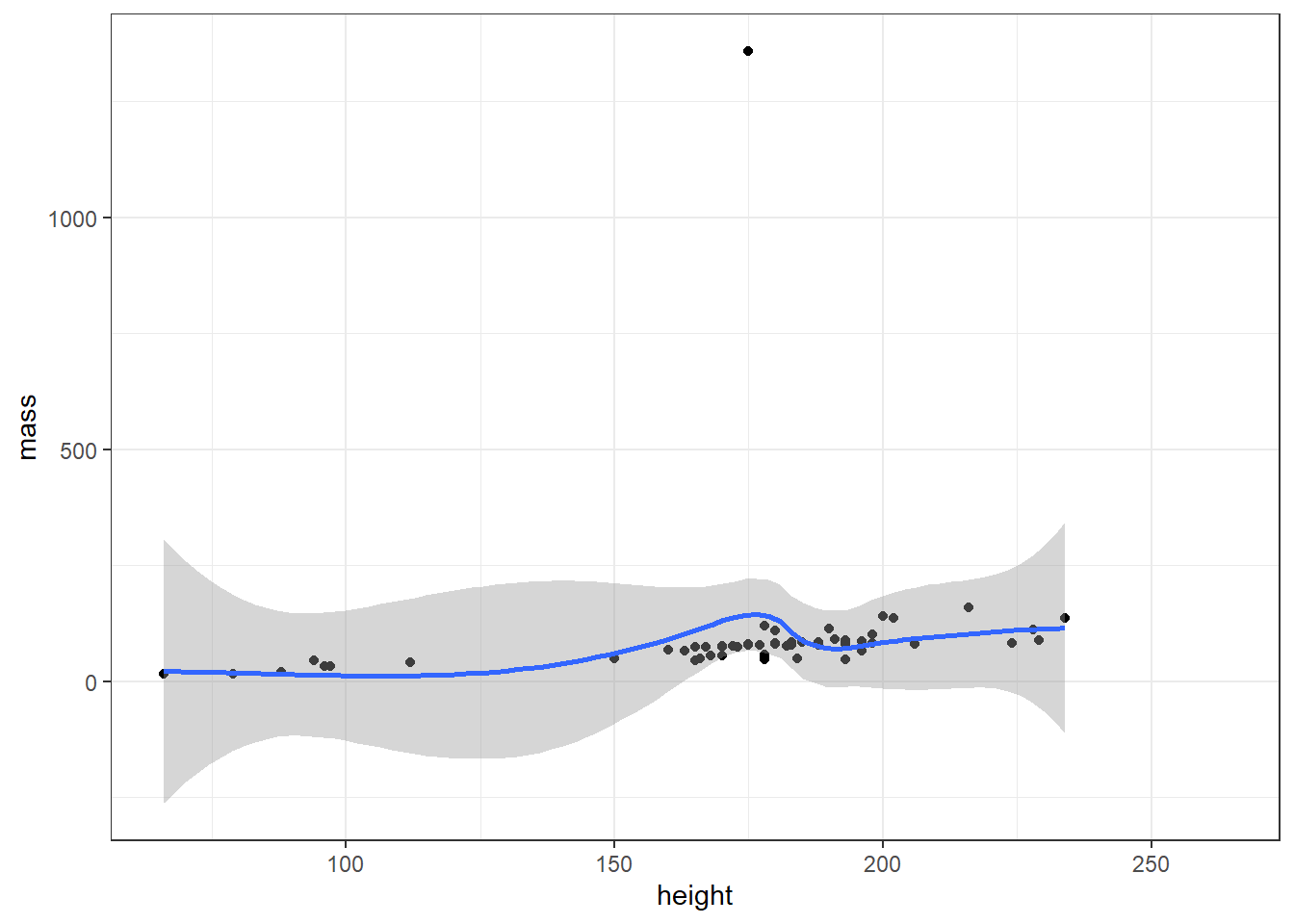
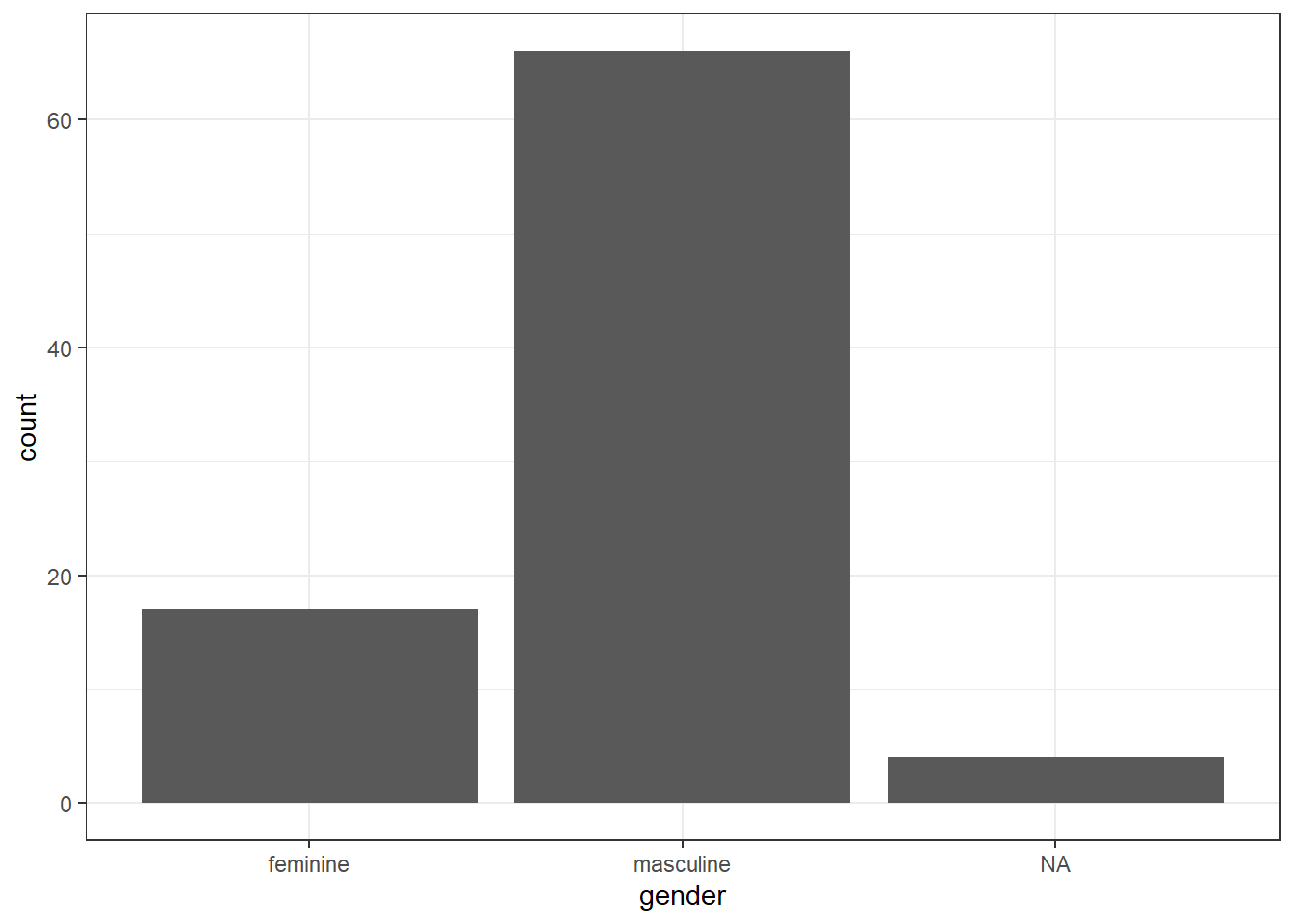
Then use the built-ingss_cat data set to create:
- A grouped density plot of age by marital status
- A violin-boxplot of age by marital status
# load data
data("gss_cat")
# grouped density
ggplot(gss_cat, aes(x = age, fill = marital)) +
geom_density(alpha = .6)## Warning: Removed 76 rows containing non-finite values (`stat_density()`).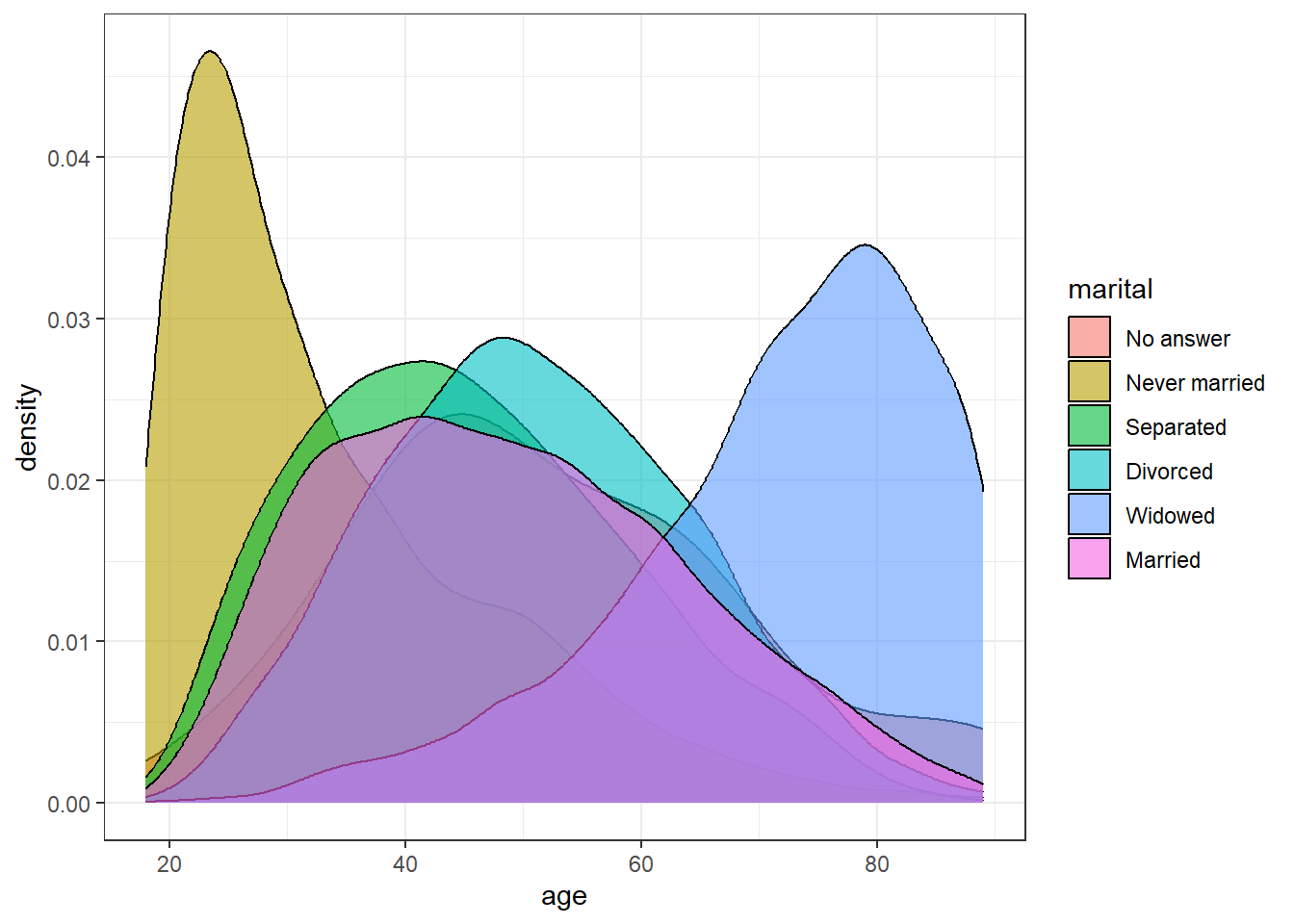
# frequency plot
ggplot(gss_cat, aes(x = age, colour = marital)) +
geom_freqpoly()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 76 rows containing non-finite values (`stat_bin()`).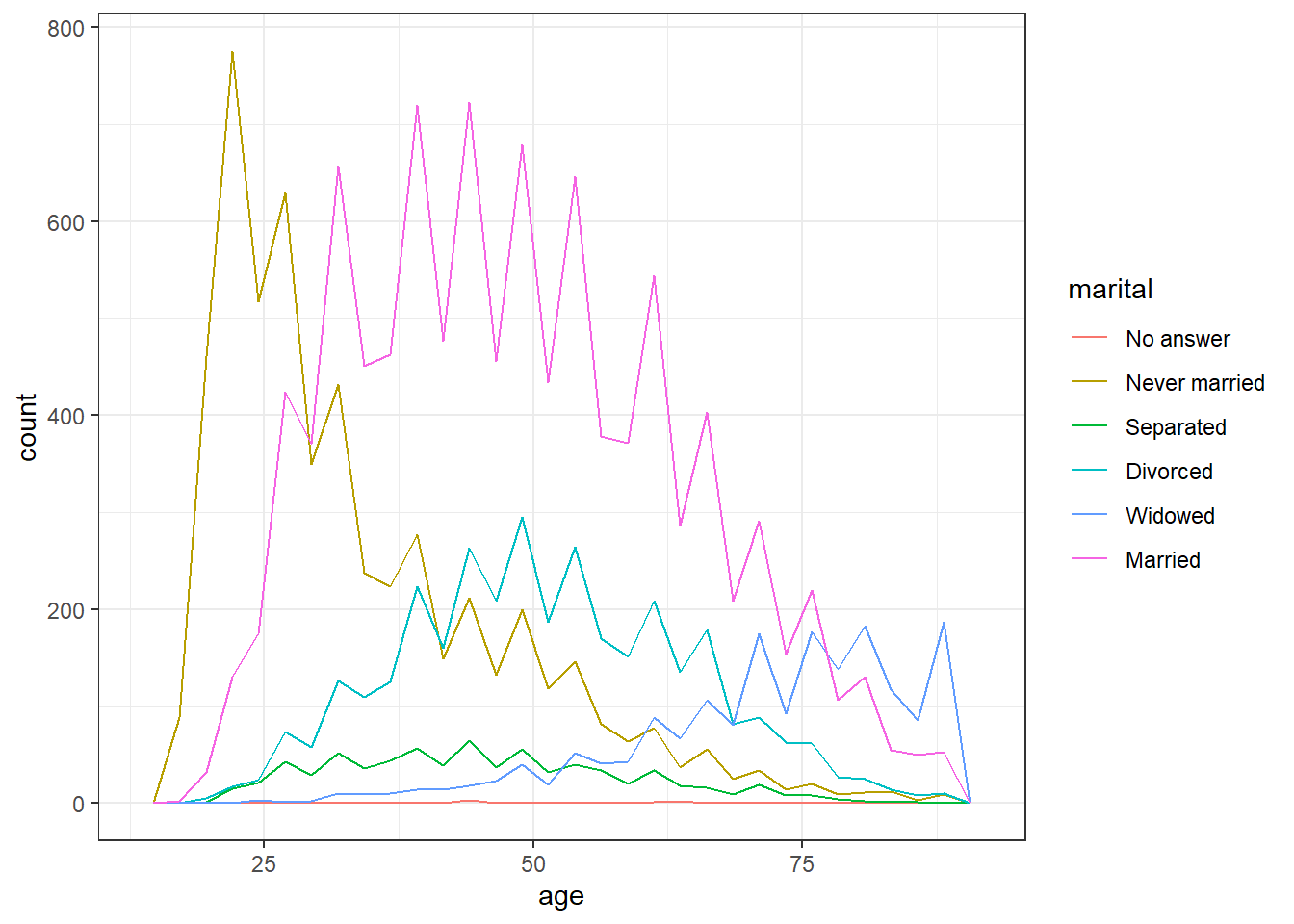
# violin-boxplot
ggplot(gss_cat, aes(x = marital, y = age)) +
geom_violin() +
geom_boxplot(width = .2)## Warning: Removed 76 rows containing non-finite values (`stat_ydensity()`).## Warning: Removed 76 rows containing non-finite values (`stat_boxplot()`).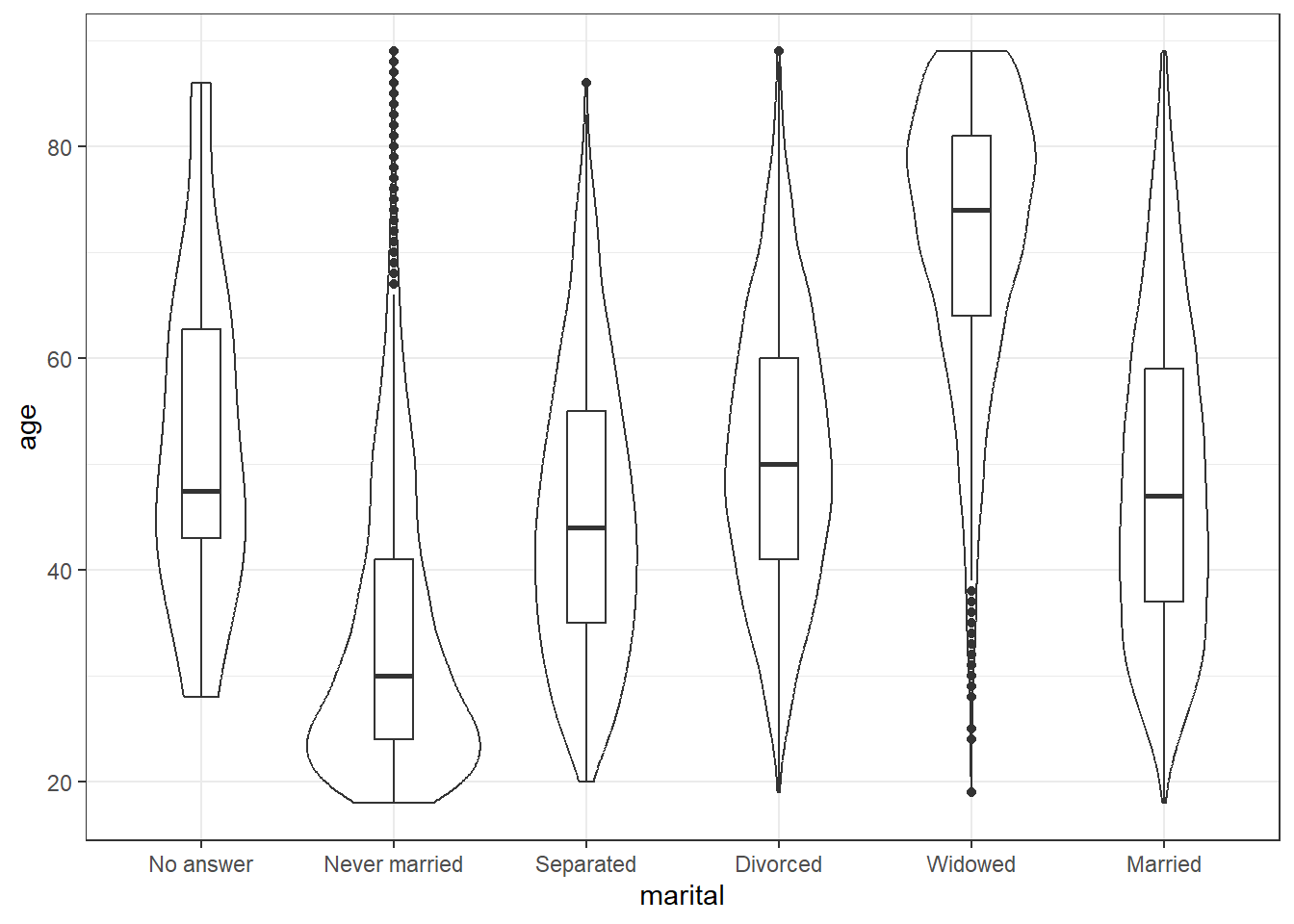
Finally, pick your two favourite plots from the above, spend some time adjusting the aesthetics (colours, themes, labels etc.), then combine them using patchwork. If you're on Twitter, share them with #APS24SF and tag (emilynordmann?)](https://twitter.com/emilynordmann).
3.10 Glossary
| term | definition |
|---|---|
| argument | |
| console | |
| continuous | |
| extension | |
| geom | |
| global environment | |
| knit | |
| median | |
| outlier | |
| project | |
| R Markdown | |
| vector | |
| working directory |
3.11 Further Resources
- R Markdown Cheat Sheet
- ggplot2 cheat sheet.
- R Markdown Tutorial
- R Markdown: The Definitive Guide by Yihui Xie, J. J. Allaire, & Garrett Grolemund
- Chapter 27: R Markdown of R for Data Science
- Project Structure by Danielle Navarro